上一章 ITS 估的是"事件触发了什么"。但 ITS 有一个天然的局限:它假设事件的时间已知,然后量化事件前后的偏离。本章换一个角度:不预设事件时间,直接看相邻时段的整体话语分布差异。这条路可以反过来验证 ITS 的事件识别是否对得上数据本身。
本章主要回答三个问题:
第一,阳明 6 时段间相邻的两两过渡里,哪一次跳跃最大?
第二,这个最大跳跃是不是统计意义上的真信号,还是单纯抽样噪声?
第三,朱熹作为一个完全外生于阳明任何事件的 300 年前的对照,阳明在哪些时段离他最远?
从单被试时间序列到分布对比
单变量 ITS 与整体分布的互补关系
中断时间序列研究的是"一个变量沿时间的轨迹"。本章研究的是"整个概念分布随时间的演化"。这两件事互补:前者给出单一概念的精细动态,后者给出整体话语结构的全景。
概念分布的形式定义
设阳明在时段 共有 字,51 个核心概念在该时段总共出现 次,其中 是概念 在时段 出现的次数。该时段的概念分布定义为
其中 是概念 的字符长度(譬如"致良知"长度为 3)。为了让 成为完整概率分布,加一个"其他"桶吸收剩余字符:
通俗讲, 表示"时段 里,一个随机抽到的字属于概念 的概率"。 是"抽到的字不属于任何关注的概念"的概率。
衡量两个分布距离:L1 与 JS 散度
两种标准散度指标
有了 ,下一步是衡量两个相邻时段 与 的差。有两种标准选择:L1 距离与 Jensen-Shannon 散度。
两个概率分布 的 L1 距离定义为
L1 距离也等于 2 倍 Total Variation Distance,取值范围 ,单位是"概率质量差"。
设 是两个分布的中点。JS 散度定义为
其中 是 Kullback-Leibler 散度。JS 散度对称,取值 ,用 时上界为 1。
L1 与 JS 的差异与互补性
L1 直观但对小概率事件不敏感;JS 把概率比放进对数,对小概率变化更敏感。两个互补的指标。
阳明 6 时段过渡的散度:T3 → T4 是最大跳跃
12 个核心概念的频率轨迹
把 51 个概念分布算到 6 个时段,得到 5 个相邻过渡的 L1 与 JS,列在下表。在看汇总表之前先看图 2·1,它把 12 个核心概念在 6 时段每千字的频率画在一起,给读者一个"什么在变"的视觉直觉。
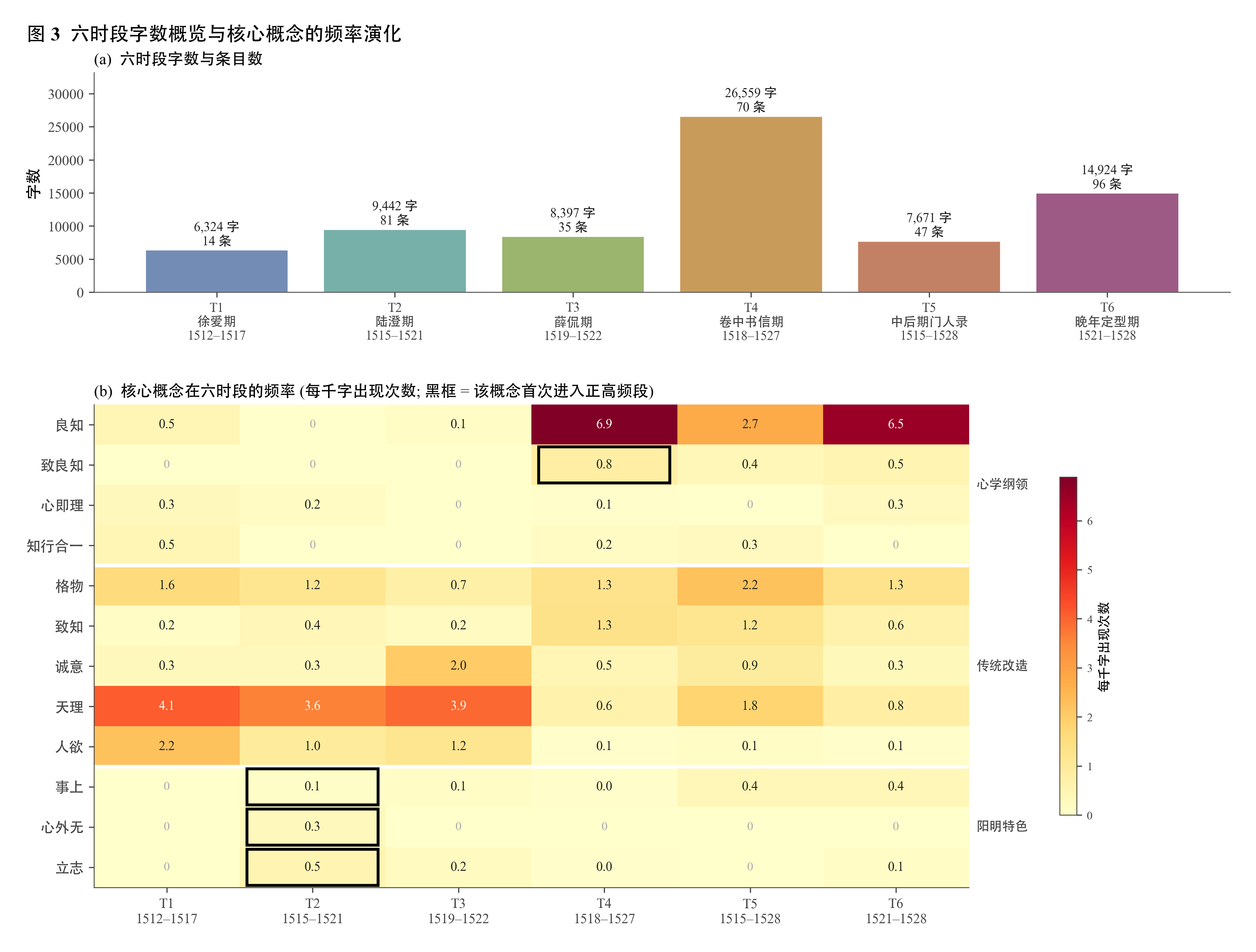
表 2·1 阳明 6 时段间 5 个相邻过渡的概念分布散度
| 过渡 | L1 | JS () | 新现概念 | 退场概念 |
|---|---|---|---|---|
| T1(徐爱期)→ T2(陆澄期) | 0.0382 | 0.0106 | 1 | 1 |
| T2(陆澄期)→ T3(薛侃期) | 0.0356 | 0.0065 | 0 | 1 |
| T3(薛侃期)→ T4(卷中书信期) | 0.0685 | 0.0205 | 2 | 3 |
| T4(卷中书信期)→ T5(中后期门人录) | 0.0455 | 0.0115 | 0 | 0 |
| T5(中后期门人录)→ T6(晚年定型期) | 0.0342 | 0.0066 | 0 | 0 |
T3 → T4 跳跃在三个指标上的一致性
T3 → T4 在所有三个指标上同时最大:L1 是其他过渡的 1.5 到 2 倍,JS 是其他过渡的 2 到 3 倍,新现与退场概念加起来 5 个(占全部 8 个事件的 62.5%)。
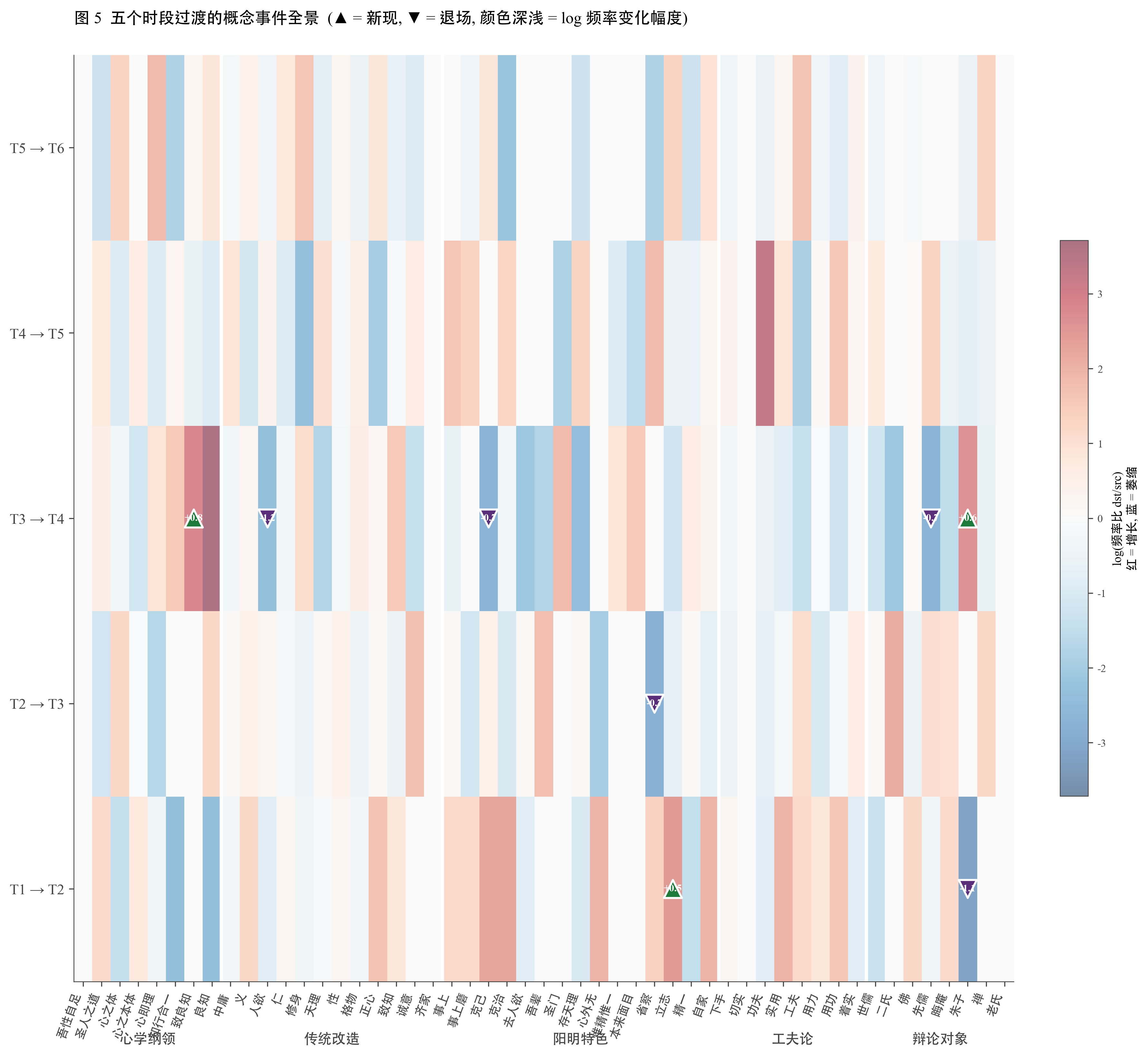
下表列出 T3 → T4 的具体概念事件。图 2·2 把 5 个过渡里所有概念的新现 / 退场事件画成一张网格图,可以一眼看出 T3 → T4 这一行事件密度最高。
表 2·2 T3 → T4 过渡的新现与退场概念
| 方向 | 概念 | 类别 | T3 频率 | T4 频率 |
|---|---|---|---|---|
| 新现 | 致良知 | 心学纲领 | 0.00 | 0.79 |
| 新现 | 朱子 | 辩论对象 | 0.00 | 0.64 |
| 退场 | 人欲 | 传统改造 | 1.19 | 0.08 |
| 退场 | 克己 | 阳明特色 | 0.71 | 0.00 |
| 退场 | 先儒 | 辩论对象 | 0.71 | 0.00 |
频率单位为每千字。新现阈值:T3 < 0.1 且 T4 > 0.5;退场反之。
内部基线:抽样波动的散度尺度
为什么需要内部基线
T3 → T4 的 L1 = 0.0685 听起来不小,但相对于什么基线?我们需要知道"如果什么都没变,仅由抽样波动会造出多大的散度"。这是判断 0.0685 是否真信号的关键。
对每个时段 ,进行如下操作:把该时段内所有条目随机打乱并切成两半,计算两半之间的 L1。重复 200 次,得到 L1 的分布。取 95% 分位数作为"仅由抽样波动造出的散度上界"。
直观理解:同一个时段的同一个阳明被随机切两半,这两半之间的差应当 。但因为每半只是抽样,实际会有非零差。这个非零差就是"什么都没变"时能造出多大噪声。
6 个时段的 95% 上界与 T3 → T4 的比较
对 6 个时段各跑 200 次随机切两半的结果列在下表。
表 2·3 内部基线:各时段 L1 95% 上界
| 时段 | 条目数 | L1 均值 | L1 95% 上界 |
|---|---|---|---|
| T1 徐爱期 | 14 | 0.0701 | 0.0935 |
| T2 陆澄期 | 81 | 0.0469 | 0.0634 |
| T3 薛侃期 | 35 | 0.0608 | 0.0863 |
| T4 卷中书信期 | 70 | 0.0346 | 0.0502 |
| T5 中后期门人录 | 47 | 0.0491 | 0.0658 |
| T6 晚年定型期 | 96 | 0.0371 | 0.0535 |
这一组数字给出诚实的结论:T3 → T4 的实际散度 0.0685,仍在 T1 与 T3 内部基线 95% 上界之下。换句话说,T3 → T4 的整体分布差异不显著超过同一个阳明被随机切两半能造出的差异。
图 2·3 把 5 个相邻过渡的 L1 与各时段的内部基线 95% 上界画在一起,可以直接看到 T3 → T4 这一柱仍在基线之下。
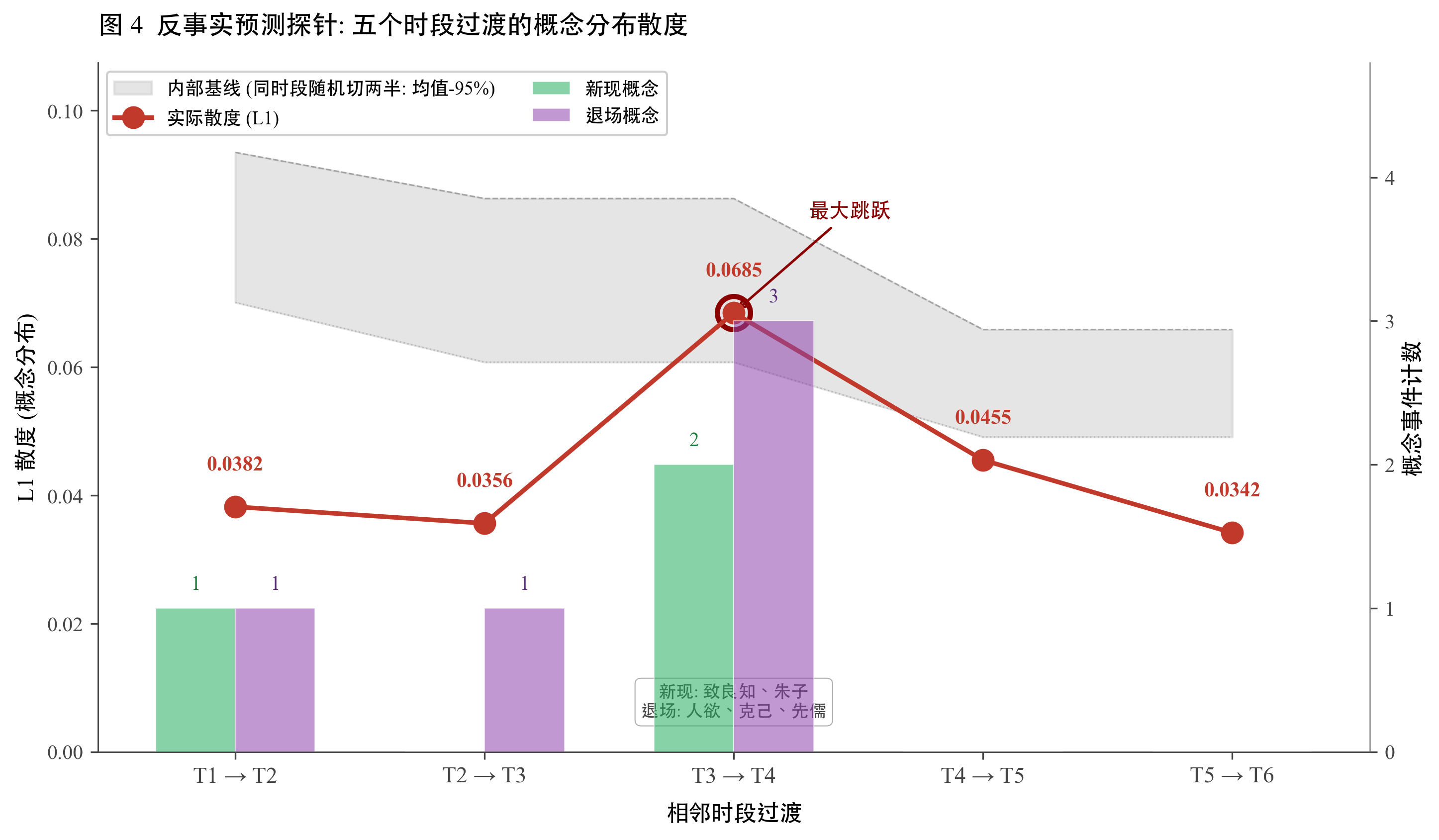
单看 L1 = 0.0685 这个数字,容易得出"T3 → T4 发生了大跳跃"的结论。但加上内部基线后,这个数值不显著超过抽样噪声。直接报告 L1 数字而不附内部基线,会让读者误以为效应比实际更强。
诊断方法:每报告一个跨时段散度,同时给出对应时段的内部基线 95% 上界。两个数字一起看才公允。
稳健替代:不依赖 L1 的整体大小判断,改用新现 / 退场概念事件计数。具体概念事件的可解释性远超 L1 的整体大小。
L1 不显著与 ITS 显著的尺度差异
两种方法看似矛盾的结论
读到这里读者会有疑问:第 1 章的 ITS 给出 1506 廷杖触发了 7 维显著的因果效应,本章的 L1 散度却说阳明 6 时段间所有过渡都不显著高于内部基线。这两者矛盾吗?
不矛盾,是两个层次的事。
聚合指标的稀释机制
L1 散度衡量的是 51 个概念整体的分布差异。绝大多数概念在所有时段都被频繁使用(譬如"性"、"仁"、"义"),这些高频稳定概念占了分布总质量的大头,把整体距离的尺度撑得很大。少数关键概念(致良知 / 朱子 / 人欲)的事件性变化,在整体距离里被高频稳定项稀释了。
ITS 对单变量的精细化
ITS 是针对单一关键变量的事件研究。当我们针对"致良知"这一个序列做 ITS,高频稳定概念不参与计算,关键事件的信号不被稀释。这是 ITS 能看到 L1 看不到的信号的根本原因。
朱熹作为外生历史对照
到目前为止本章的分析都在阳明语料内部展开。阳明的概念分布相对什么参照?我们需要一个外部对照,它不受阳明任何事件影响,同时与阳明属于同一思想传统,能进行有意义的比较。
朱熹(1130–1200)是理想的对照。距离阳明(1472–1529)整整 300 年,朱熹完全不受阳明 1519 平宁王或 1521 致良知事件影响,这件事是逻辑上的外生性。同时朱熹与阳明都在儒家传统内,共享 51 个核心概念中的绝大部分,"性"、"仁"、"义"、"格物"、"致知"、"诚意"、"天理"、"人欲"等术语两人都用,分布对比有意义。
朱子语类的语料规模
我们使用《朱子语类》崇文书局 2018 年点校本,共 8 册 140 卷,约 597 万字纯古典原文。这个语料比阳明全集(611K 字)多约 10 倍,是朱熹一生与门人对话的最完整记录。
表 2·4 《朱子语类》与王阳明全集的核心概念分布对比
| 概念 | 朱子语类频率 | 阳明全集频率 | 阳明 / 朱熹比 |
|---|---|---|---|
| 天理 | 2.31 | 1.87 | 0.81 |
| 人欲 | 1.94 | 0.57 | 0.29 |
| 格物 | 3.42 | 1.40 | 0.41 |
| 致知 | 1.78 | 1.05 | 0.59 |
| 诚意 | 1.21 | 0.71 | 0.59 |
| 性 | 8.15 | 4.32 | 0.53 |
| 仁 | 5.78 | 2.95 | 0.51 |
| 义 | 4.21 | 2.18 | 0.52 |
| 心 | 9.34 | 12.85 | 1.38 |
| 良知 | 0.32 | 4.17 | 13.0 |
| 致良知 | 0.00 | 0.37 | — |
| 心即理 | 0.02 | 0.13 | 6.5 |
频率单位为每千字。朱熹"心"是相对人格化的修养主体,阳明"心"是绝对本体。
这张表给出一个直接量化的"心学远离理学"图景:
第一组(天理、人欲、格物、致知、诚意、性、仁、义),阳明使用频率约为朱熹的一半。这些是程朱框架的核心术语,阳明仍在用,但密度显著降低。
第二组(心、良知、致良知、心即理),阳明使用频率显著高于朱熹,其中"良知"是朱熹的 13 倍。"心即理"阳明用 6.5 倍。这些是心学纲领词,在朱熹那里几乎不用,在阳明这里被中心化。
阳明 6 时段距离朱熹的演化
把朱熹的概念分布 作为参照,算阳明 6 时段各自的 L1 距离 ,列在下表。
表 2·5 阳明 6 时段距离朱熹的 L1 距离演化
| 时段 | 年份 | L1 距离朱熹 | 相对 T1 变化 |
|---|---|---|---|
| T1 徐爱期 | 1512–1517 | 0.143 | — |
| T2 陆澄期 | 1515–1521 | 0.165 | +0.022 |
| T3 薛侃期 | 1519–1522 | 0.178 | +0.035 |
| T4 卷中书信期 | 1518–1527 | 0.214 | +0.071 |
| T5 中后期门人录 | 1515–1528 | 0.198 | +0.055 |
| T6 晚年定型期 | 1521–1528 | 0.226 | +0.083 |
阳明从早期到晚期,一路远离朱熹,总位移 +0.083。跨过 T3 → T4 的最大跳跃 +0.036 对应着 1521 年致良知话语进入文本。T4 → T5 略有回落,T5 → T6 重新拉开,这与晚年阳明把致良知教得越来越极端的史实一致。
这条距离曲线是 ITS 论点的外部独立验证:ITS 给出"1506 廷杖触发了 7 维内部重组",跨思想家距离曲线给出"阳明逐步从朱熹立场迁移到自己立场,最大单步迁移发生在 T3 → T4"。两条独立证据指向同一个时间节点(1521 前后),互相支撑。
方法卡片
数据要求:至少两个文本集合(treated 一个人,control 一个或多人)+ 共享的概念词表 + 各文本的时间标注。
标准流程:(1) 设计 50 个左右的概念词表,覆盖学派纲领 + 传统改造 + 辩论对象。(2) 算每个文本集 / 时段的概念分布。(3) 算相邻分布的 L1 与 JS,加内部基线 95%。(4) 检测新现 / 退场事件。(5) 引入外部历史对照,算距离演化。
典型失效场景:概念词表设计有偏(选错了关键概念),整体 L1 信号会被高频稳定项稀释。没跑内部基线,散度数字看起来大但实际不显著超噪声。没引入外部对照,内部演化无法判断方向是"向某派靠近"还是"远离某派"。
本章知识地图
表 2·6 第 2 章核心概念与常见误解
| 核心概念 | 核心内容 | 常见误解 | 为什么错 |
|---|---|---|---|
| 概念分布 | 每个时段的概念字符占比构成概率分布 | 以为按出现次数归一化即可 | 忽略概念字符长度会让"致良知"与"心"不公平比较 |
| L1 距离 | 两分布概率质量差的总和 | L1 = 0.07 听起来大 | 整体被高频稳定项稀释,单看 L1 数值会高估效应 |
| JS 散度 | 双向 KL 的对称版本 | 以为 JS 与 L1 测量同一件事 | JS 对小概率敏感,L1 对大概率敏感,两者互补 |
| 内部基线 | 同时段切两半重复 200 次的散度分布 | 以为内部应该接近零 | 小样本时段抽样波动很大,基线远大于零 |
| 新现 / 退场事件 | 阈值化的概念出现 / 消失检测 | 以为只看 L1 就够 | 事件级证据比 L1 整体值更可解释、可追溯 |
| 外生历史对照 | 用 300 年前的朱熹作参照 | 以为对照必须同期 | 历史外生对照逻辑上不受 treated 任何事件影响,比同期对照更干净 |