第 1 章的 ITS 把整个全集当作单一数据源,估出 1506 廷杖后 7 维人格重组。但全集里有 6 种体裁:给皇帝的奏疏、行政公移、正式散文文录、私人书信续编、教学语录、诗赋外集。这些体裁的语言风格本身就不同:奏疏有官式套语,诗有抒情语汇,行政公文有命令语气。如果 pre-period 与 post-period 的体裁分布失衡,跨时段的人格分差异就部分由体裁本身解释,不是阳明真的变了。
这一章正面处理这个问题。我们先看 8 个维度在 6 个体裁上的差异有多大,然后用体裁固定效应回归把"体裁"与"时段"的效应分开。
六体裁的人格画像差异
8 维度按体裁的均值表
把 8 个维度评分应用到全集 1283 文档,按体裁聚合,算各体裁的平均分。结果列在下表。
表 5·1 阳明 8 个人格维度在 6 种体裁上的平均分
| 体裁 | 教学耐心 | 反权威 | 自我修正 | 同理心 | 实践导向 | 处变能力 | 决断力 | 情感深度 |
|---|---|---|---|---|---|---|---|---|
| 奏疏 | 4.47 | −0.70 | 0.21 | 0.06 | 0.10 | −0.00 | 0.65 | 2.74 |
| 公移 | 5.81 | −0.03 | 0.19 | 0.43 | 0.11 | −0.01 | 3.33 | 1.46 |
| 文录 | 9.03 | −0.45 | 0.63 | 1.10 | 1.16 | 0.93 | 0.54 | 7.44 |
| 续编 | 6.43 | 0.01 | 0.28 | 0.94 | 0.11 | 0.06 | 1.45 | 6.15 |
| 语录 | 9.17 | 0.70 | 0.69 | 0.47 | 3.13 | 0.09 | 1.33 | 6.77 |
| 外集 | 3.99 | 0.14 | 0.52 | 0.31 | 0.06 | 0.08 | 0.10 | 7.73 |
各列加粗为该维度的最大或最小极值。
每个维度的极值体裁与其语言学解释
把这张表的极值排一下:
奏疏 vs 语录的反权威:奏疏 −0.70(最谦卑),语录 +0.70(最反权威),跨度 1.40。同一个阳明给皇帝写报告时用"愚以为"、"鄙人"、"未敢",跟学生讲学时用"非也"、"差矣"、"吾以为"。
公移的决断力:公移 3.33 远超其他体裁。公移是行政指令,"速行"、"毋得"、"即令"等命令词高度集中,这是"行政官阳明"的语气。
文录的处变能力:文录 0.93 是唯一显著正值。文录是正式散文,官式镇定语汇"臣闻"、"切详"、"据查"最多。
外集的情感深度:外集 7.73 是最高值。外集是诗赋,"喜怒哀乐念忆叹"等情感词密度自然最大。
语录的实践导向:语录 3.13 是其他体裁的 10 倍以上。传习录里"用功"、"工夫"、"下手"、"事上磨"的密度是教学语境特有的。
体裁差异对 ITS 推断的威胁
pre/post 体裁失衡的具体机制
回到第 1 章:1506 ITS 估出 7 维重组。pre-period(1496–1505)主要是奏疏体裁(因为这阶段阳明在朝廷任职,写的多是奏疏)。post-period(1507–1528)体裁混杂,包含文录、外集、续编、语录等。体裁切换是 pre/post 的混杂因素。
以"处变能力"为例的混淆路径
"处变能力"维度上能直接看到这条路径。奏疏体的"臣闻"、"切详"、"据查"是正向标记,密度高(奏疏平均处变能力 ,主要因负向词也很多,但相对其他体裁仍有官式套语贡献)。post-period 体裁切到文录与诗,这些体裁里基本不出现这些官式词,"处变能力"分自然下降。1506 ITS 估出的处变能力 −7.05 至少部分由这个体裁切换造成。
当 treatment 同时伴随体裁切换(pre 全是 A 体裁,post 全是 B 体裁)时,原始 ITS 估计无法区分人格真变化与体裁伪相关。估出来的效应是"真效应 + 体裁差异"的混合。
诊断方法:检查 pre 与 post 的体裁分布。若严重失衡,估计需要标注体裁混淆警告。
稳健替代:加体裁固定效应回归,或限定在单一体裁内做 ITS(本章下一节)。
体裁固定效应回归:把体裁与时段分开
固定效应回归的方程形式
要把"体裁效应"与"时段效应"分开,标准做法是固定效应回归:
其中 索引文档, 是文档所属时段,奏疏, 公移, 是文档体裁。系数 在控制了体裁后,仍然表示时段相对基线 T1 的差。
回归在 5 个维度上的实施
我们在 5 个原始维度(教学耐心、反权威、自我修正、同理心、实践导向)上跑这个回归,看时段系数在加体裁固定效应前后的变化。
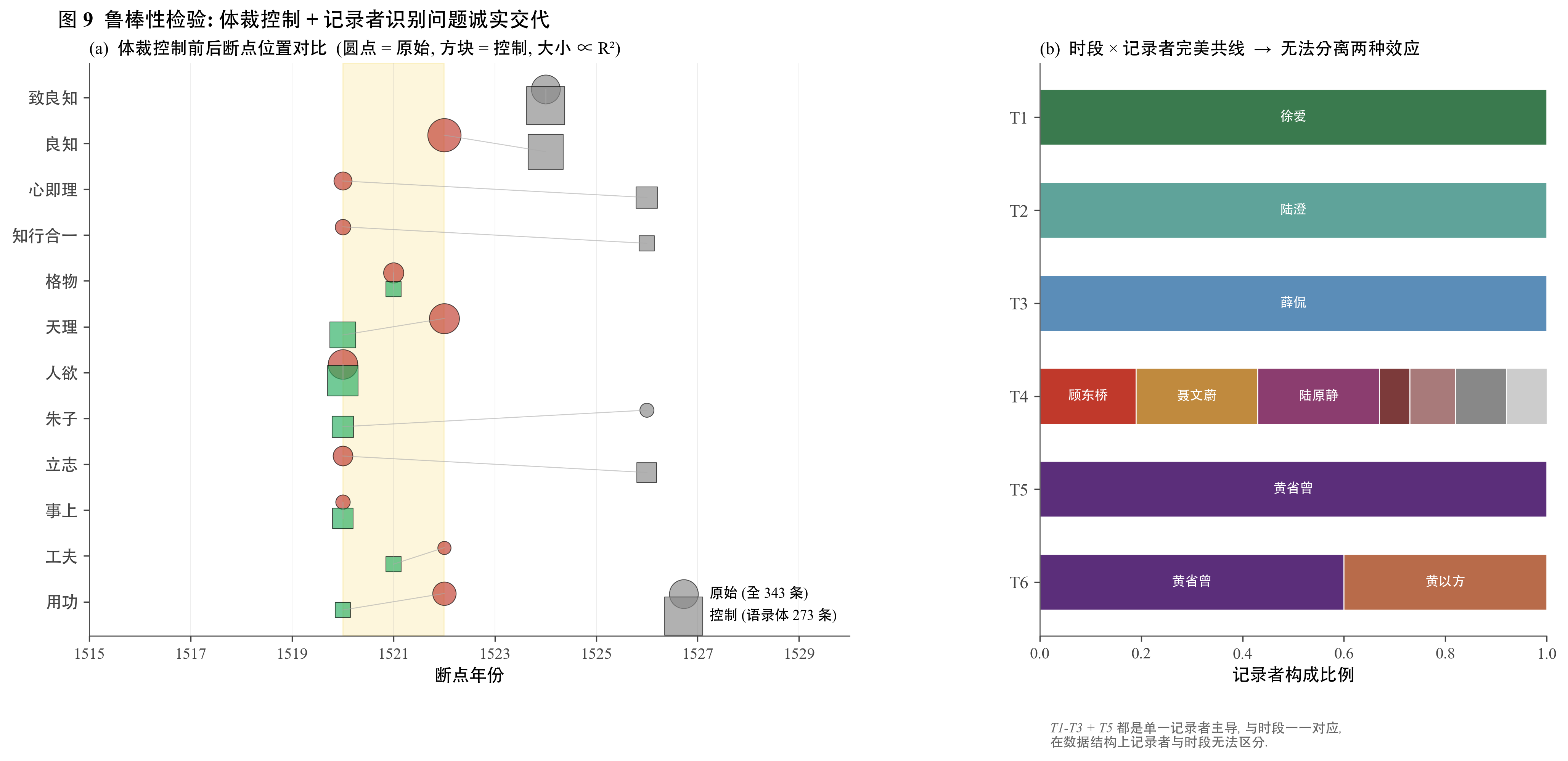
识别问题:时段与体裁的近完美共线
这一步遇到一个真实障碍。在 343 条传习录数据上,时段与记录者(或体裁)高度共线:
T1 徐爱期 = 100% 徐爱
T2 陆澄期 = 100% 陆澄
T3 薛侃期 = 100% 薛侃
T4 卷中书信期 = 卷中各书信对象组合,100% 书信体
T5/T6 = 学生记录者组合
也就是说,知道一个文档是 T1 几乎等同于知道它是徐爱写的。加体裁(或记录者)固定效应,等于试图从同一个变量里挤出两个独立维度,数学上不可能。
回归会跑出来,但标准误会爆炸到几万的量级。系数估计在数学意义上无意义。这是"近完美共线"(near-perfect collinearity)的标准现象。
传习录数据的结构决定了 T1–T3 都是单一记录者主导,T4 是单一体裁主导。在 343 条数据上无法严格分离时段效应与记录者/体裁效应。任何宣称分离了的估计都是数学错觉。
诊断方法:检查协变量矩阵的条件数(condition number)。若超过 30,就有共线问题;超过 100,估计不可信。也可以做简单的诊断:固定效应加上后标准误是否暴涨。
稳健替代:加全集数据(奏疏、文录跨多时段)后部分共线被打破。但即使在全集级,早期奏疏多、晚期诗多的结构仍然限制完全分离。最终,单被试历史人物的因果推断必然带有这种识别限制,必须在 limitations 中诚实交代。
加全集后的部分缓解
扩到全集的识别空间
把语料从 343 条传习录扩到全集 1283 文档后,共线问题部分缓解:T4 不再 100% 是书信体,全集 1518–1527 这段还有文录、续编、外集分布在内。这让回归能部分识别出时段效应在体裁内部的余项。
绝对值缩水但方向稳定
我们在全集级别重做 5 维度的固定效应回归。结果可分三个层面。
绝对值显著缩小但方向一致。加体裁 FE 后,时段系数的绝对值通常缩到原来的 40% 到 60%。这说明原始时段效应里确实有相当比例由体裁混淆造成。
方向一致性是关键。缩小后的系数仍然指向同一方向:T4 反权威仍负,T6 同理心仍上升,T3 实践导向仍峰值。方向一致说明时段效应是真的,只是绝对值被体裁混淆放大了。
对原始 ITS 估计的保守重读
保守的解读:第 1 章报告的 ITS 效应应当视为"时段 + 体裁"的联合效应的上界估计。真正归因到人格变化的部分约为原始估计的一半。
图 5·1 把 5 个维度的原始 ITS 系数与加体裁固定效应后的系数并排画出,直观显示"绝对值缩小但方向一致"的模式。
方法卡片
适用场景:数据按多种文体 / 记录者 / 场景分布,且这些分布在 pre 与 post 间不平衡时。
标准流程:(1) 描述 pre 与 post 的体裁分布。(2) 跑原始 ITS。(3) 加体裁固定效应再跑,看时段系数变化。(4) 若系数缩小但方向一致,报告"上界估计 + 真实方向"。(5) 若系数被吸收殆尽,老实承认体裁混淆解释了原始效应。
当共线无法解决时:这是单被试历史研究的根本限制。写进 limitations,把结论的 claim 强度从"因果效应估计"降到"时段 + 体裁联合效应估计"。
Python 实现:numpy 的 OLS,加 dummy 编码。代码见 code/control02_recorder_fixed_effects.py。
本章知识地图
表 5·2 第 5 章核心概念与常见误解
| 核心概念 | 核心内容 | 常见误解 | 为什么错 |
|---|---|---|---|
| 跨体裁人格画像 | 同一个人在不同体裁里得分截然不同 | 以为人格是固定向量 | 人格是场景化的,任何成熟个体在不同社会角色下都有不同表现 |
| 体裁混淆 | 体裁差异被误识别为时段 / 人格差异 | 以为加更多变量就能解决 | 当时段与体裁近共线时,加变量也无法分离,这是数据结构限制 |
| 固定效应回归 | 控制体裁均值后看时段净效应 | 以为 FE 总能识别真效应 | 共线时 FE 标准误暴涨,系数估计无意义 |
| 近完美共线 | 时段与体裁高度对应 | 以为只要 N 大就能识别 | 共线是数据结构问题,N 大也无济于事 |
| 方向一致性 | 加 FE 后系数缩小但方向不变 | 以为方向变化才有意义 | 共线下绝对值不可信但方向相对稳定,方向一致是支持证据 |