盈余管理度量在做一件什么事
会计实证研究里有一类问题反复出现:上市公司公布的会计利润里,有多少来自经营本身,有多少来自管理层在会计政策、估计、与交易时点上的主动选择。这个问题被称为盈余管理度量。它的输出是一个 firm-year 级别的连续变量,即可操纵性应计,记 DA。DA 越大,研究者认为这一年度的会计利润里来自管理层主观选择的成分越多。盈余管理度量与舞弊检测的二分类、与政策效应估计的因果识别是三件不同的事,本书全程只做度量这一件。
给定一家公司 在第 年的财报数据,盈余管理度量是一个函数 ,把可观测的会计变量映射到一个标量 。 越大,表示在这一年的应计或真实经营决策中,归因于管理层主动选择的部分越多。
这是一个度量问题,不是检验问题。研究者不要求 在零水平上做出舞弊与非舞弊的判别;他们要求 在同一组比较公司中给出相对排序,作为后续回归(如盈余管理与公司治理、并购前操纵、IPO 操纵等研究中的代理变量)的左侧或右侧变量。
应计与现金的会计身份
在会计利润等式里,净利润分两部分:
其中 NI 是净利润,CFO 是经营活动现金流,TA 是总应计,英文称 total accruals。这个等式的成立来自复式记账:所有不直接发生在当期现金科目的收入或支出,都要通过应计科目入账。换句话说,TA 衡量的是利润里没有以现金兑现的部分。
应计本身没有方向问题。一家正常经营的公司应有持续的正向应计:信用销售导致应收增加、库存周转导致存货变动、固定资产折旧逐期分摊。盈余管理研究关心的是另一件事:给定一家公司当年的真实经营状况,TA 应该是多少;实际观察到的 TA 与这个应有值之间的差距,被称为可操纵性应计 DA:
其中 NDA 表示非操纵性应计,英文称 non-discretionary accruals。本书介绍的十种方法,差别全部在 NDA 怎么估。Healy 1985 用样本均值估,Jones 1991 用行业-年份回归估,Dechow-Dichev 2002 用前后期 CFO 估,Roychowdhury 2006 不估应计而估真实经营变量如现金流、生产成本、可酌情费用应有的水平。
Hribar-Collins 资产负债表方法
经营现金流 CFO 在现金流量表上直接报告,但在 1987 年 SFAS 95 之前,美国上市公司不强制披露现金流量表。早期文献用资产负债表方法构造 TA:
其中 是流动资产变化、 是现金及现金等价物变化、 是流动负债变化、 是短期债务变化、 是应付税金变化、 是当期折旧与摊销。这个公式背后的会计逻辑是:流动应计等于流动资产中非现金部分的变化,减去流动负债中非融资性、非税务性部分的变化,再扣掉非现金的折旧。
Hribar 与 Collins 指出,这种资产负债表方法在公司发生兼并、出售、外币折算或调整重述时会产生系统性误差。他们建议改用现金流量表方法:
直接用利润表的 NI 减去现金流量表的 CFO,避免资产负债表项目的非经营性变化干扰。这个改动让此后绝大多数英文盈余管理文献都改用现金流量表方法。
本书面临一个数据约束。本书使用的公开数据集 Bao et al. (2020) 来自 Compustat,但仅包含 28 个原始会计字段,不含现金流量表项目 oancf。因此本书使用资产负债表方法构造 TA,并用 倒推合成 CFO。这与 Hribar-Collins 改进方向相反,但在没有 oancf 字段时是唯一可行的路径。
当一家公司在第 年发生大额并购时,流动资产、流动负债、存货、应收等项目会因合并报表而发生大幅跳变,资产负债表方法会把这些跳变当作应计计入。Hribar 与 Collins 在 1988–1997 年样本上发现,资产负债表 TA 与现金流量表 TA 在并购年平均偏差可达样本标准差的 1/3。本书因数据约束无法切换到现金流量表方法,因此在 Enron 1997 年合并 Portland General 等并购窗口里,TA 估计会偏离真实值。诊断方法:在每章末尾交叉对照该公司 TA 是否在某一年出现单点跳变;如有,把该年标注为可疑年并与该公司公开披露的并购历史核对。
数据与样本构造
本书使用 Bao et al. (2020) 发表在 Journal of Accounting Research 的公开数据集。该数据从 WRDS Compustat North America Annual Fundamentals 抽取,覆盖 1991–2014 年美国上市公司,共 146,045 个 firm-year 观测,包含 27 个原始会计字段以及 SEC 会计与审计执法公告匹配的舞弊标签,公告简称 AAER。数据可从 github.com/JarFraud/FraudDetection 直接下载,无需 WRDS 订阅。
剔除规则两条:第一,行业上沿用 Compustat 抽取时已剔除金融业 SIC 6000–6999 的设定;第二,要求 at、sale 均不为空且大于零,要求滞后总资产 lag_at 有定义,要求资产负债表 TA 可计算。剔除后剩余 119,187 firm-year 观测,覆盖 15,451 家公司,年均 4,966 firm-year。各年样本量分布相对稳定,1991 年 3,971 行、1995 年 5,218 行、2014 年 4,383 行。
派生字段如下。lag_at 取 at 按 gvkey 的上一年值。TA_BS 按上一节公式构造,再除以 lag_at 得到缩放后的 TA。CFO_s 用 合成。dSale_s、dRect_s、PPE_s、Sale_s 分别是销售变化、应收变化、固定资产、本期销售缩放到 lag_at 后的值。WC_accr 是把折旧加回 TA_BS 得到的营运资金应计,第 6 章 Dechow-Dichev 使用。PROD_s 是 COGS 加存货变化缩放到 lag_at,第 9 章 Roychowdhury 使用。所有缩放后的比率变量在 1% 与 99% 分位上 winsorize,控制极端 firm-year 对回归的影响。
Bao 2020 数据相对 WRDS 直接拉取的限制
公开数据相比直接订阅 WRDS 拉取的 Compustat,有三处取舍。一是缺少行业代码 sich。Jones 1991 等方法的标准做法是按 SIC 两位行业 fyear 分组跑回归,本书因此改为按 fyear pooled,把所有行业放在一起估。这一简化在第 3 章正文里会再次说明,并讨论它对估计结果的影响方向。二是缺少现金流量表项目 oancf 与 ivncf,本书用合成 CFO 替代。三是缺少销售与一般行政费用 xsga、研发 xrd、广告 xad,第 9 章 Roychowdhury 真实活动 EM 因此只实现异常 CFO 与异常 PROD 两个分量,可酌情费用 DISEXP 分量留作扩展讨论。
案例公司:三起 SEC AAER 处罚案件
为让十种方法的对比有具体落点,本书选取三家被 SEC AAER 处罚的舞弊公司,覆盖小、中、大三种规模。
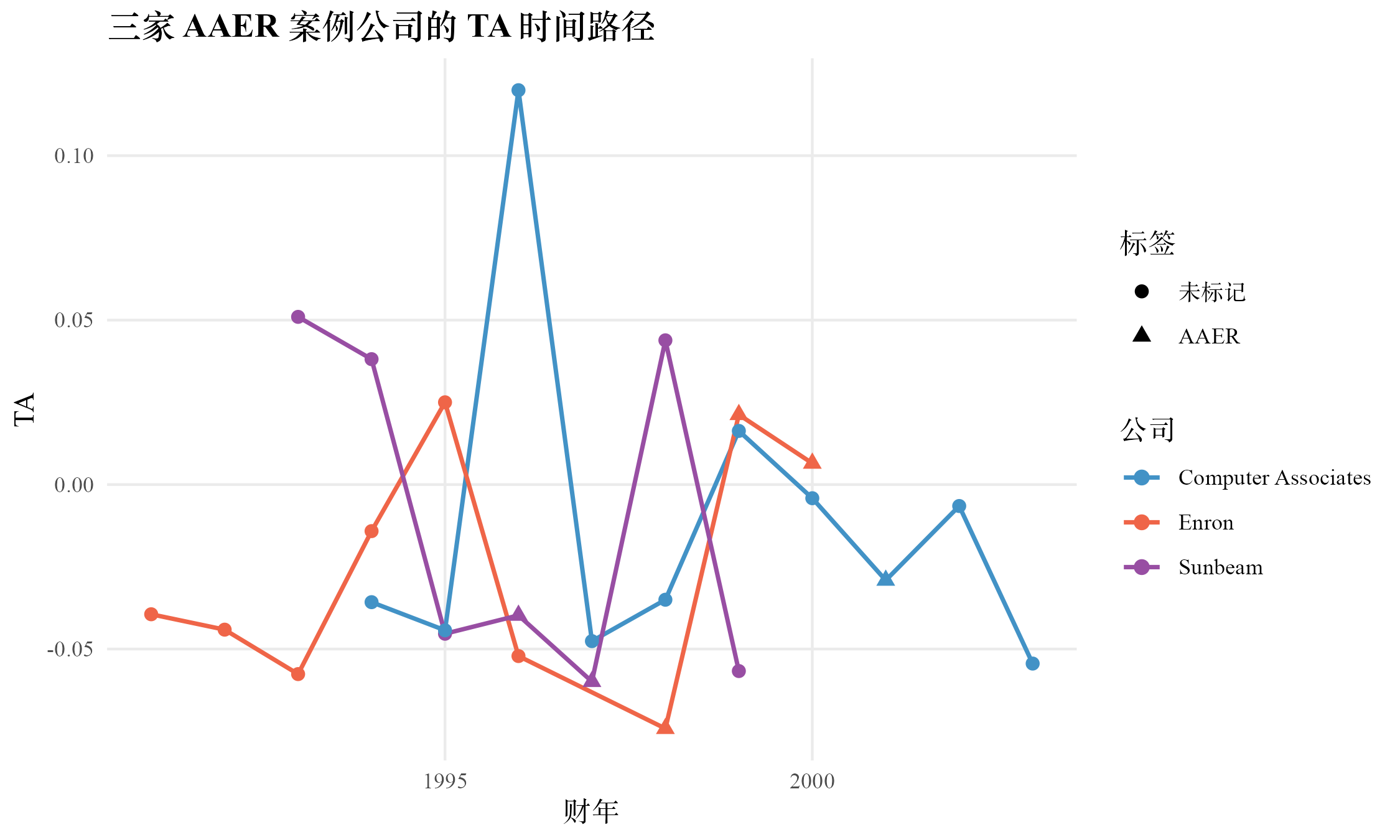
1996–1997 年间,Sunbeam 在 CEO Al Dunlap 主导下大量使用 cookie jar reserves 与 channel stuffing(向分销商压货)虚增收入与利润。1996 年公司报告净亏损 1.97 亿美元(实际经营本就在恶化),1997 年急速反弹至 5,230 万美元净利润。SEC 在 2001 年起诉 Dunlap 等管理层。本书在第 2–10 章观察十种 DA 方法能否在 1996 与 1997 年把 Sunbeam 排到分布右尾。
2000 年前后,公司被指控通过提前确认软件许可证收入(35-day month 操纵)系统性高估营收。2001 财年报告营收 426 亿美元,2002 财年急剧下降至 55 亿。SEC 在 2004 年达成和解,公司被罚 2.25 亿美元。Computer Associates 是中等规模、营收侧操纵的典型案例,第 8 章 Stubben 收入侧 DA 在它身上的表现尤其关键。
1998–2001 年间,Enron 通过特殊目的实体即 SPE 转移负债、夸大收入、虚增交易额。2000 财年营收 1,008 亿美元,比 1996 年的 133 亿增长七倍以上;2001 年 12 月公司破产。Enron 是大型综合舞弊案,应计型与真实活动型操纵兼有,本书第 9 章 Roychowdhury 与第 10 章 F-Score 的综合判别都把它作为压力测试。
表 1·1 给出三家公司在关键年份的基础财务切片。可以看到三家公司在规模上跨越两个数量级,但在原始 TA / lag_at 这一指标上数值都落在 这个看似 平淡的窄区间,仅靠这个单一指标看不出舞弊嫌疑。这正是后续方法存在的必要性所在:从原始 TA 的窄区间里,分离出真正属于管理层选择的部分。
表 1·1 三家案例公司的基础财务切片
| 公司 | fyear | at ($M) | sale ($M) | ib ($M) | TA | ROA |
|---|---|---|---|---|---|---|
| Sunbeam | 1996 | 1,073 | 984 | −197 | −0.040 | −0.170 |
| Sunbeam | 1997 | 1,059 | 1,073 | 52 | −0.060 | 0.049 |
| Computer Associates | 2001 | 25,168 | 42,613 | 404 | −0.029 | 0.019 |
| Enron | 1998 | 29,350 | 31,260 | 703 | −0.074 | 0.044 |
| Enron | 1999 | 33,381 | 40,112 | 1,024 | 0.021 | 0.035 |
| Enron | 2000 | 65,503 | 100,789 | 979 | 0.006 | 0.029 |
R 与 Python 双实现规范
本书代码以 R 为主,Python 等价代码在每章末尾的 Python 实现一节给出。两者在关键统计量上对齐到小数点后四位。随机种子统一设为 2026:R 用 set.seed(2026),Python 用 np.random.seed(2026) 加 random.seed(2026)。
第 1 章数据加载与基础描述统计的 R 实现如下。
# code/ch01_overview.R 主体
suppressPackageStartupMessages({
library(tidyverse); library(here); library(ragg)
})
set.seed(2026)
source(here::here("code", "_theme.R"))
source(here::here("code", "_load_panel.R"))
p <- load_em_panel()
ta_stats <- p |> summarise(
mean = mean(TA, na.rm = TRUE),
median = median(TA, na.rm = TRUE),
sd = sd(TA, na.rm = TRUE),
q1 = quantile(TA, 0.25, na.rm = TRUE),
q3 = quantile(TA, 0.75, na.rm = TRUE)
)
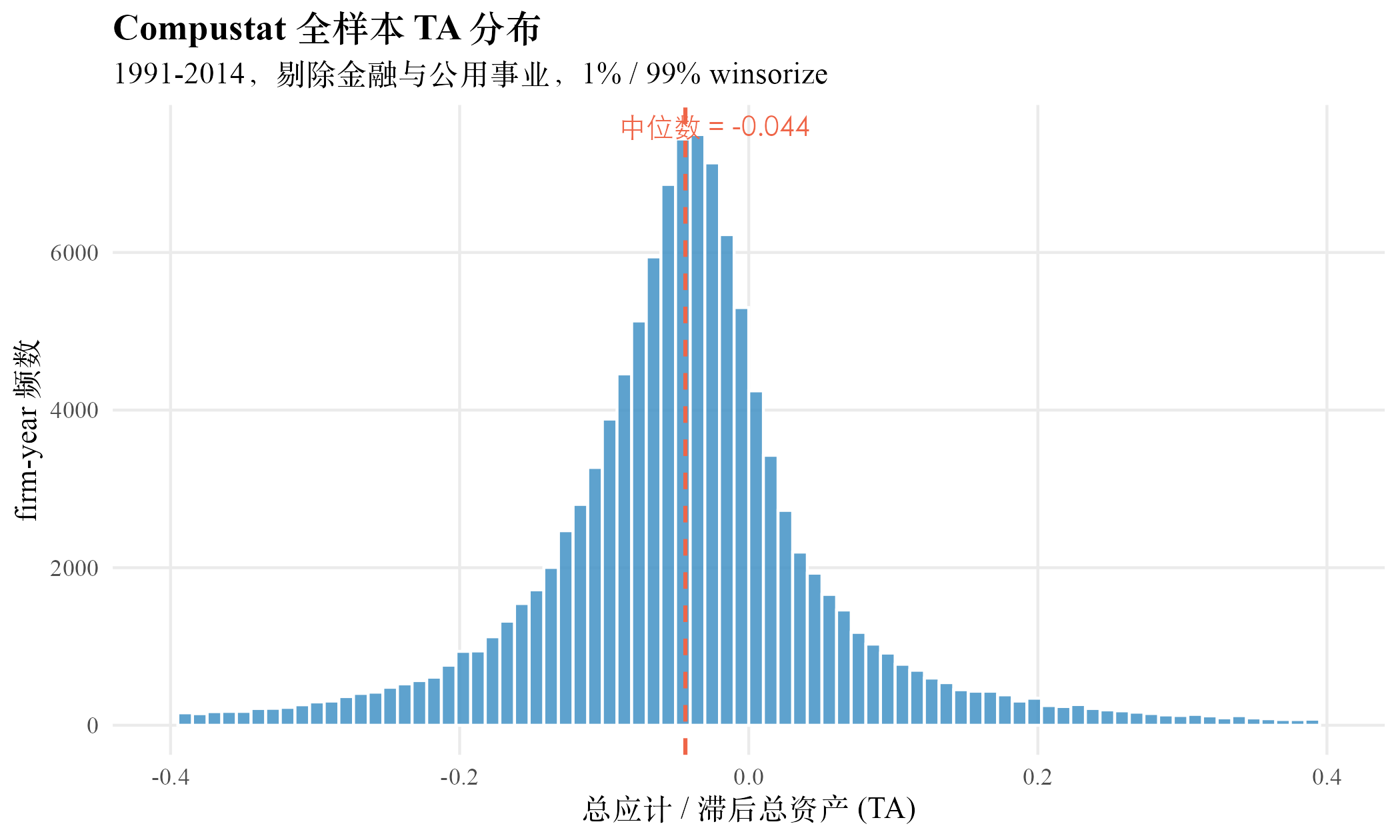
全样本 TA 均值 、中位 ,与会计文献关于美国上市公司 TA 普遍为负的经验事实一致。负值的会计含义是折旧与摊销在大多数公司中超过流动应计的增长,长期看应计在反向消化资本支出。标准差 0.192 反映 firm-year 之间存在相当大的横截面异质性,这正是后续每一种方法试图把异质性分解为非操纵成分与可操纵成分的起点。
下图把全样本 TA 的频率分布画出来。绝大多数 firm-year 集中在 与 之间,分布略偏右尾。极端右尾的 firm-year 是后续每一种方法都需要解释的对象。
下图把三家案例公司的 TA 时间路径画出来。Sunbeam 在 1996 年 TA 跌至 、1997 年继续走低至 后在 1998 年急速反弹至 ,对应 SEC 文件中 1997 年提前释放储备的描述。Enron 1998–2000 年 TA 持续低位,2000 年回归至接近零,对应那一年大量营收来自交易而非应计。Computer Associates 的 TA 在 2001 年附近波动较小,但第 8 章会看到它的营收侧 DA 在 1995–1998、2001–2002 多次进入分布右尾。
Python 实现
Python 端的等价加载与 TA 描述统计如下。本书全程使用 pandas、numpy、statsmodels、scikit-learn 这一组标准组合。
# code/ch01_overview.py
import pandas as pd, numpy as np, random
np.random.seed(2026); random.seed(2026)
p = pd.read_csv("data/em_panel.csv")
ta_stats = p["TA"].agg(["mean", "median", "std",
lambda s: s.quantile(0.25),
lambda s: s.quantile(0.75)])
print(ta_stats)
R 与 Python 输出的 TA 均值 、中位 、标准差 0.1920 完全一致,下游每一章的关键统计量也都对齐到小数点后四位。
本章累积对比表
第 1 章尚未引入任何 DA 度量方法,累积对比表此处只列出方法占位与本书数据基线。
表 1·2 累积对比表(第 1 章占位)
| 方法 | 样本量 | DA mean | DA sd | 案例公司平均分位 |
|---|---|---|---|---|
| 基线 TA | 119,187 | −0.0513 | 0.1920 | —— |
| Healy 1985 | —— | —— | —— | —— |
| DeAngelo 1986 | —— | —— | —— | —— |
| Jones 1991 | —— | —— | —— | —— |
| Modified Jones | —— | —— | —— | —— |
| PM-DA | —— | —— | —— | —— |
| Dechow-Dichev | —— | —— | —— | —— |
| McNichols | —— | —— | —— | —— |
| Stubben | —— | —— | —— | —— |
| Roychowdhury RM | —— | —— | —— | —— |
| F-Score / ML | —— | —— | —— | —— |
本章知识地图
表 1·3 第 1 章核心概念与常见误解
| 核心概念 | 核心内容 | 常见误解 | 为什么错 |
|---|---|---|---|
| 盈余管理度量 | 把 firm-year 的财报映射到 DA 这个连续标量,越大越像被操纵 | 等同于舞弊检测 | 度量是连续排名,舞弊检测要求二分类边界;前者服务于回归代理,后者服务于监管决策 |
| 总应计 TA | 净利润中未以现金兑现的部分,会计身份 | TA 为正才是被操纵 | 正常经营的公司通常有正向流动应计,TA 本身只是会计身份的一部分 |
| 可操纵性应计 DA | 实际 TA 与给定经营状况下应有的 TA 之差 | 同一家公司每年应有相近的 DA | DA 的非操纵性部分会随销售、固定资产、行业景气循环变化,恒定假设是 Healy 1985 的简化 |
| 资产负债表 TA | 用 构造 | 与现金流量表 TA 数值一致 | 并购、外币折算、报表重述会使两者在单一 firm-year 上出现 20% 以上的偏差 |
| 合成 CFO | 当 oancf 缺失时用 倒推 | 是真实经营现金流的无偏估计 | 资产负债表 TA 的误差会全部进入合成 CFO,需要在 Roychowdhury 章节里复检 |
| AAER 标签 | SEC 会计与审计执法公告匹配的 firm-year 标签 | 等于实际舞弊年份 | AAER 通常追溯到处罚前若干年,时间窗与实际操纵窗未必完全重合 |
小结
本章把后续九章共用的数据基础与方法立场交代清楚。本书使用 Bao 2020 公开数据,覆盖 1991–2014 年 15,451 家美国上市公司共 119,187 firm-year 观测,AAER 涉案 firm-year 占 0.73%。本书的度量目标是 firm-year 级别的连续 DA 代理变量,不是二分类舞弊检测;评价标准在于不同方法在同一组案例公司上的相对排名一致性与方法间相关性,不在于单点估计的统计显著性。三家案例公司 Sunbeam、Computer Associates、Enron 将作为后续每一章的统一测试对象。第 2 章从最早的 Healy 1985 与 DeAngelo 1986 开始,把 用样本均值或上年值估非操纵性应计 这个最朴素的思路展开,看看它在三家案例公司上能给出什么样的初步答案。