从 Jones 系列切换到 DD 系列
第 3 章到第 5 章的 Jones / Modified Jones / Performance-Matched 都属于"基于销售与固定资产解释应计、残差作为 DA"的同一框架,差别仅在解释变量与配对方式。Dechow 与 Dichev 提出的应计质量度量切换到一个完全不同的视角:应计的本质是把当期收入与成本归到当期,与前期、当期、后期的现金流应该有结构性对应关系。如果一家公司的应计能被三期现金流稳定解释,说明会计估计准确;如果应计与三期现金流的关系飘忽不定,说明会计估计存在大量误差,盈余质量低。
这个视角带来三个具体改动。第一,回归形式不同:DD 用前期 CFO、当期 CFO、后期 CFO 三个解释变量。第二,输出层次不同:Jones 系列给每个 firm-year 一个 DA 值,DD 给每家公司一个稳定的应计质量指标(公司级、不是 firm-year 级)。第三,方法学定位不同:Jones 系列直接度量可操纵性应计,DD 度量应计估计质量,两者相关但不等价。
Dechow-Dichev 模型的定义
对所有 firm-year 跑 pooled OLS:
其中 是营运资金应计、、、 分别是前期、当期、后期经营现金流,均除以 缩放。
公司 的应计质量为残差按公司分组的标准差:
越大,应计估计误差越大,盈余质量越差。
营运资金应计 WC_accr 是把折旧从总应计中加回得到的指标,含义是不包含非现金折旧的纯流动应计。本书在 code/00_load_data.R 里直接构造好 WC_accr = (TA_BS + dp) / lag_at,避免在每章重新计算。
Dechow 与 Dichev 原文的 AQ 计算按公司在估计窗口(连续 5 年)内残差标准差,得到一个滚动时间序列。本书简化为按公司全样本残差标准差,要求公司至少有 5 年观测。这一简化让每家公司只输出一个 AQ 值,便于跨公司比较,但失去了 AQ 随时间变化的动态信息。
在 Bao 数据上的实现
p2 <- p |>
arrange(gvkey, fyear) |>
group_by(gvkey) |>
mutate(CFO_lag = lag(CFO_s), CFO_lead = lead(CFO_s)) |>
ungroup() |>
filter(!is.na(WC_accr), !is.na(CFO_lag), !is.na(CFO_s),
!is.na(CFO_lead))
fit <- lm(WC_accr ~ CFO_lag + CFO_s + CFO_lead, data = p2)
p2$resid_dd <- residuals(fit)
quality_by_firm <- p2 |>
group_by(gvkey) |>
filter(n() >= 5) |>
summarise(n = n(), AQ_dd = sd(resid_dd))
回归样本 90,189 firm-year,损失主要来自后期 CFO 不可得的最后一年观测。回归结果:
表 6·1 DD pooled OLS 回归系数
| 变量 | 估计 | 标准误 | 值 |
|---|---|---|---|
| Intercept | 0.0098 | 0.0005 | 19.0 |
| CFO_lag | 0.0451 | 0.0011 | 41.5 |
| CFO_t | −0.108 | 0.0012 | −89.9 |
| CFO_lead | 0.0784 | 0.0011 | 70.7 |
。系数方向与 DD 原文一致:当期 CFO 系数负(应计与当期现金流互为镜像,一边多了另一边就少),前期与后期 CFO 系数正(前后期现金流通过应收应付与本期应计正向耦合)。
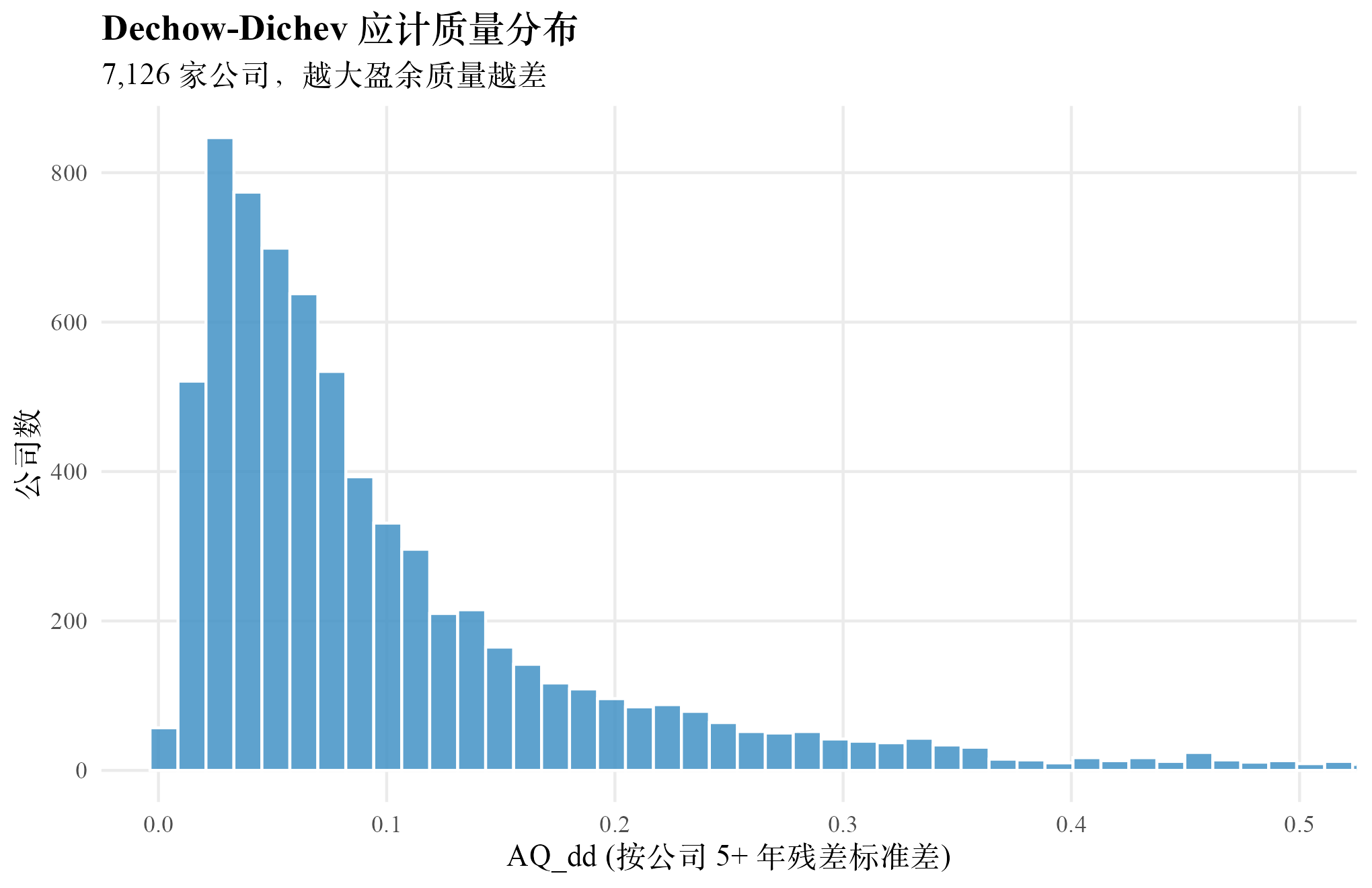
约 10%,意味着三期 CFO 只能解释营运资金应计的 10% 变异,剩下 90% 留给残差。这看似很低。DD 的设计目的是把那 10% 可由现金流匹配解释的「非估计误差」成分剥离出去,让剩下的 90% 残差代表应计估计误差, 的绝对水平本身不是优化目标。AQ_DD 的统计:7,126 家公司满足至少 5 年观测要求,均值 0.109、中位 0.0704、标准差 0.114、p10 0.0231、p90 0.244。
图 6·1 DD 两步结构:pooled OLS 得 firm-year 残差,按公司聚合得 AQ。完整 TikZ 图详见 PDF 全文。
下图把 7,126 家公司的 AQ_DD 分布画出来。形态严重右偏,大多数公司集中在 AQ_DD < 0.1 的低估计误差区域,少数公司分布到 0.2 以上的右尾。
案例公司的 AQ_DD
DD 给出的是公司级指标,单个 firm-year 没有独立的 AQ 值,只有残差。下表把三家案例公司的 AQ_DD 与全样本分位列出。
表 6·2 案例公司应计质量 AQ_DD
| 公司 | 可用年数 | AQ_DD | mean_resid | 全样本分位 |
|---|---|---|---|---|
| Sunbeam | 5 | 0.0408 | 0.0249 | 0.272 |
| Computer Associates | 19 | 0.0453 | 0.00129 | 0.308 |
| Enron | 7 | 0.0306 | −0.000173 | 0.173 |
数据告诉我们三家 AAER 公司的 AQ_DD 都没有进入右尾。Enron 的 AQ_DD 仅 0.0306,在全样本中排在 17% 分位,盈余质量看起来比大多数公司还好。这一结果与 SEC 文件描述形成强烈反差,但与 DD 方法学的特性一致:
DD 度量的是应计估计误差的稳定性,不是单期 DA 的绝对水平。Enron 1998–2000 年的盈余管理高度一致地朝同一方向(虚增收入),残差的"标准差"反而稳定地小,AQ_DD 因此被低估。如果一家公司的盈余管理风格忽左忽右(如本期推迟、下期提前),AQ_DD 才会显著扩大。系统性、单向的盈余管理是 DD 方法的盲区。
Dechow 等在综述中明确指出,AQ_DD 与 SEC AAER 标签的相关性在大样本研究里普遍很弱。原因是 DD 度量的是估计误差波动,而 AAER 案例的核心特征是系统性虚增或压低,这种系统性偏差恰好不增加残差波动。误用方式:把 AQ_DD 直接作为舞弊筛查指标,期望 AAER 公司排在右尾。诊断方法:在 AAER 样本与对照样本上分别计算 AQ_DD 分位分布,如果两者重合度很高,说明 DD 在该样本上无判别力,需切换到 Jones 系列或第 10 章的综合 F-Score。DD 的核心适用场景是盈余质量与公司治理、信息环境、融资成本的关联研究,不是直接的舞弊检测。
Python 实现
# code/ch06_dechow_dichev.py
import pandas as pd, numpy as np, statsmodels.api as sm
p = pd.read_csv("data/em_panel.csv").sort_values(["gvkey","fyear"])
p["CFO_lag"] = p.groupby("gvkey")["CFO_s"].shift(1)
p["CFO_lead"] = p.groupby("gvkey")["CFO_s"].shift(-1)
p2 = p.dropna(subset=["WC_accr","CFO_lag","CFO_s","CFO_lead"])
X = sm.add_constant(p2[["CFO_lag","CFO_s","CFO_lead"]])
fit = sm.OLS(p2["WC_accr"], X).fit()
print(fit.summary().tables[1])
p2 = p2.assign(resid_dd = fit.resid)
aq = (p2.groupby("gvkey").filter(lambda d: len(d) >= 5)
.groupby("gvkey")["resid_dd"].std()
.reset_index().rename(columns={"resid_dd": "AQ_dd"}))
print(aq["AQ_dd"].describe().round(4))
R 与 Python 端 DD 回归系数、、AQ_DD 描述统计均一致。
本章累积对比表
表 6·3 累积对比表(第 6 章末)
| 方法 | 样本量 | DA / AQ mean | DA / AQ sd | 案例公司舞弊年份平均分位 |
|---|---|---|---|---|
| 基线 TA | 119,187 | −0.0513 | 0.1920 | —— |
| Healy 1985 | 119,187 | 0.0000 | 0.1910 | Sunbeam 0.17 / CA 0.49 / Enron 0.49 |
| DeAngelo 1986 | 103,736 | −0.0038 | 0.2480 | Sunbeam 0.13 / CA 0.23 / Enron 0.31 |
| Jones 1991 | 119,187 | −0.0110 | 0.1860 | Sunbeam 0.23 / CA 0.01 / Enron 0.53 |
| Modified Jones 1995 | 119,187 | −0.0104 | 0.1870 | Sunbeam 0.24 / CA 0.09 / Enron 0.44 |
| PM-DA 2005 | 119,187 | ≈ 0 | 0.2530 | Sunbeam 0.24 / CA 0.67 / Enron 0.28 |
| DD 2002 (公司级 AQ) | 7,126 公司 | 0.109 | 0.114 | Sunbeam 0.27 / CA 0.31 / Enron 0.17 |
| McNichols | —— | —— | —— | —— |
| Stubben | —— | —— | —— | —— |
| Roychowdhury RM | —— | —— | —— | —— |
| F-Score / ML | —— | —— | —— | —— |
本章知识地图
表 6·4 第 6 章核心概念与常见误解
| 核心概念 | 核心内容 | 常见误解 | 为什么错 |
|---|---|---|---|
| 应计质量 | 营运资金应计与前后期 CFO 关系的残差标准差 | 同 DA 一样是 firm-year 级 | AQ 是公司级指标,把多年残差聚合到一个标准差,反映估计误差的稳定性 |
| 三期 CFO | 前期、当期、后期 CFO 解释应计的会计身份 | 当期 CFO 一项就够 | 应收与应付分别对应前后期,缺一会让残差携带可解释成分 |
| 仅 10% | 三期 CFO 只能解释 10% 营运资金应计变异 | 低说明方法不行 | DD 的目的是把 10% 可解释部分剥出,剩下 90% 留作估计误差, 低是设计目的 |
| 公司级输出 | 每家公司只有一个 AQ 值 | 不能与 firm-year 级 DA 比较 | 第 10 章把 DD 残差按 firm-year 单独作为 DA_dd 使用,与其他方法对齐 |
| 系统性盈余管理盲区 | 一致方向的虚增不增加残差波动,AQ 反而小 | AAER 公司应该有大 AQ | Enron AQ 仅 0.031,排在 17% 分位,与 SEC 描述反差大 |
| 方法学定位 | 盈余质量、信息环境、融资成本研究的代理变量 | 直接的舞弊检测工具 | Dechow 综述明确该指标与 AAER 标签相关性弱,不适合舞弊筛查 |
小结
本章把 Dechow-Dichev 2002 应计质量在 Bao 数据上跑通。pooled OLS 得到 ,三期 CFO 系数方向与原文一致。7,126 家公司的 AQ_DD 均值 0.109、中位 0.0704。三家 AAER 案例公司的 AQ_DD 都没有进入右尾,Enron 的 AQ_DD 仅 0.0306(17% 分位),反映 DD 方法学对系统性单向盈余管理不敏感。DD 的核心适用场景是盈余质量与公司治理、信息环境、融资成本的关联研究,作为舞弊筛查工具效率较低。下一章 McNichols 在 DD 的三期 CFO 基础上再加销售变化与固定资产,把 Jones 系列与 DD 系列融合,是本书最综合的应计型 DA 度量。