从 Healy 到 Jones:剩余的两个噪声源
第 2 章 Healy 横截面变体把同一 fyear 全样本的 TA 均值当作非操纵性应计,剩下的偏差就归到 DA。这个做法在三家案例公司上的表现并不令人满意:Sunbeam 在 1996--1997 被排到左尾,但 Enron 与 Computer Associates 的舞弊年份分位都集中在中位附近。
Healy 把哪些信号留在了 DA 里没拆出来?两件事。一件是固定资产强度:重资产公司每年因折旧而产生的非现金成本远高于轻资产公司,TA 整体偏负。Healy 用同年全样本均值减一刀,重资产公司被减掉的均值偏小,剩余 DA 仍然带着资产结构的痕迹。另一件是销售增长:销售增长的公司因为信用销售扩张、存货周转加快,应收、存货、应付都会同步抬高,TA 正向波动。这些都属于经营本身的合理变化,不该算到 DA 头上。
Jones 把这两个变量显式放进回归。她在研究美国国际贸易委员会 ITC 调查期间公司是否通过盈余管理影响关税决定时,发现 Healy 的横截面均值无法区分"行业普遍下行带来的应计萎缩"与"管理层主动压低利润以争取保护性关税"。她提出按行业 SIC 两位代码与年份分组跑 OLS 回归,用残差作为 DA。这个做法此后成为 1990 年代以后盈余管理实证研究的事实基线。
Jones 模型的定义
对每个行业 年份组合 ,跑横截面 OLS:
DA 为回归残差:。
其中 是公司 在第 年的总应计、 是滞后一期总资产、 是销售相对上年的变化、 是当年固定资产毛额。所有变量在回归前都除以滞后总资产 ,目的是控制公司规模带来的异方差,让重资产大公司与轻资产小公司的应计在同一尺度上做比较。
注意回归没有截距项。截距项被吸收到 这一项里,等价于在缩放前的水平方程中允许一个公司规模相关的常数。这种写法是 Jones 原文的设计,背后假设是非操纵性应计的常数部分本身随公司规模而变。
Bao 数据的行业控制限制
Jones 原文按 SIC 两位行业 fyear 分组跑回归。本书使用的 Bao (2020) 公开数据集不含行业代码 sich,无法严格按行业-年份分组。本书改为按 fyear 单维分组,即每年把全样本所有公司放在一起跑一次 OLS,得到当年的 后回代到该年所有 firm-year 上求残差。
这个简化会让 Jones DA 携带行业平均水平的偏差:石油公司与软件公司的应计结构差异极大,把它们混到一起估系数,得到的系数是行业加权平均,并不能完全拟合任一行业的真实关系。具体方向上,对于固定资产相对全样本均值偏高的行业,PPE 系数被低估,DA 偏负;对于销售变化幅度偏大的行业,ΔSale 系数被低估,DA 偏正。这是公开数据相比 WRDS 直拉的真实代价。
但在另一面,pooled 估计并没有破坏方法的对比逻辑。本书第 10 章关心的是九种方法在同一份样本上的相对排名一致性,行业偏差对所有方法的影响方向相同。读者若有 WRDS 订阅,把 code/00_load_data.R 替换为直拉版本并加入 sich 字段,仅需修改一行 group_by(fyear) 为 group_by(sich2, fyear) 即可。
在 Bao 数据上的实现
R 实现用 tidyverse 的 group_by-nest-map 模式,把每年作为一个嵌套子集,单独跑 OLS。完整脚本在 code/ch03_jones.R。
jones_by_year <- p |>
filter(!is.na(TA), !is.na(dSale_s), !is.na(PPE_s)) |>
group_by(fyear) |>
nest() |>
mutate(
fit = map(data, ~ lm(TA ~ 0 + inv_lag_at + dSale_s + PPE_s,
data = .x)),
n = map_int(data, nrow),
r2 = map_dbl(fit, ~ summary(.x)$r.squared)
)
# 把残差合回原数据
jones_with_da <- jones_by_year |>
mutate(data2 = map2(data, fit, ~ mutate(.x, DA_jones = resid(.y)))) |>
select(fyear, data2) |> unnest(data2) |> ungroup()
跑完得到 24 个年度回归,平均样本量 4,966 firm-year,平均 ,中位 。这个 水平是 Jones 模型的典型数值。Jones 原文按行业-年份分组的 通常在 0.10 到 0.20 之间,因为应计的可解释部分本来就只占 TA 总方差的一小部分,大部分变异留给了 DA。
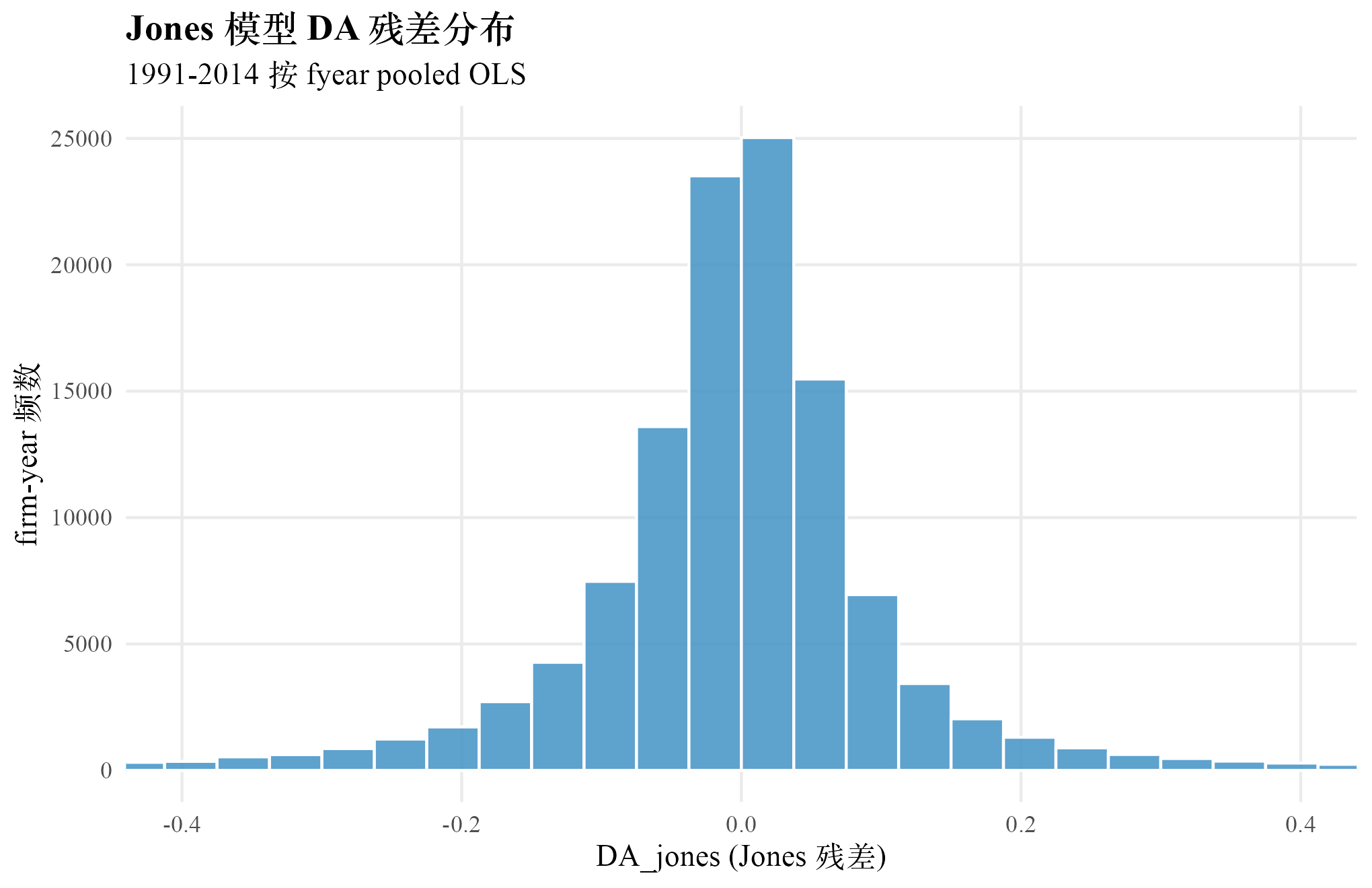
DA_jones 全样本统计:n 119,187,均值 、中位 、标准差 0.186、p10 、p90 0.111、绝对值均值 0.0993。绝对值均值 0.0993 比第 2 章 Healy 的 0.104 略低 5%,反映 Jones 模型把销售与固定资产的可解释成分剥出去之后,DA 的"纯净度"有所提升。提升幅度并不大,部分原因是按 fyear pooled 的简化没能用上行业-年份分组的更细控制,模型解释能力受限。
图 3·1 Jones 模型的三步流水线:三个解释变量 、、 经按 fyear pooled OLS 估计,残差即 DA。完整 TikZ 图详见 PDF 全文。
下图把 DA_jones 的全样本分布画出来。形态近似对称、轻微偏右,p10 与 p90 的覆盖范围 到 与第 2 章 Healy 的 到 接近。
案例公司在 Jones 下的表现
把三家 AAER 公司在 Jones 模型下的 DA 估计列出,与第 2 章 Healy 对照。
表 3·1 案例公司舞弊年份的 DA_Jones 估计与同年分位
| 公司 | fyear | AAER | DA_Jones | rank_Jones | rank_Healy (对照) |
|---|---|---|---|---|---|
| Sunbeam | 1996 | ✓ | 0.024 | 0.079 | |
| Sunbeam | 1997 | ✓ | 0.434 | 0.255 | |
| Computer Associates | 2001 | ✓ | 0.011 | 0.493 | |
| Enron | 1998 | ✓ | 0.676 | 0.290 | |
| Enron | 1999 | ✓ | 0.417 | 0.610 | |
| Enron | 2000 | ✓ | 0.508 | 0.564 |
数据告诉我们三件事。Sunbeam 1996 年在 Jones 下的分位 0.024 比 Healy 下的 0.079 更靠左尾,与 SEC 文件所述压低当期利润的方向更一致;这说明 Jones 把 Sunbeam 那年的销售下滑解释掉一部分之后,剩下的 DA 信号更纯。Enron 1998 年在 Jones 下分位提升到 0.676(右尾),明显比 Healy 下的 0.290 改进,Jones 捕捉到了 Enron 应计中无法用销售扩张解释的部分。Computer Associates 2001 年在 Jones 下分位 0.011 极其靠左,这一结果出乎意料,原因可能在于 2001 年 CA 大幅扩张应收账款,Jones 模型把这部分扩张当作合理的销售相关应计吸收了。Modified Jones 在下一章会把应收变化从销售变化中扣掉,对 CA 的判别会有改善。
舞弊年份的平均同年分位:Sunbeam 0.229、Computer Associates 0.011、Enron 0.534。Sunbeam 与 Enron 的方向都对,CA 的方向反了。三家公司平均分位 0.258,仍未稳定地排到右尾。
研究者最常见的错误是把 DA_jones 的绝对值直接当成"管理层调高 / 压低利润的金额"。这是错的。Jones 残差是经销售与固定资产解释后剩余的应计偏差,里面除了真实的盈余管理,还包含三类与盈余管理无关的成分:(1)行业内未被销售与固定资产捕捉的差异,比如服务业的劳动密集应计;(2)一次性会计事项,如重组费用、资产减值;(3)按 fyear pooled 时未控制的行业固定效应噪声。诊断方法:把 DA_jones 对一组已知的非操纵性变量做回归,看 。如果 仍超过 0.05,说明残差里还有相当部分系统成分,不能直接当作操纵规模来引用。研究中的标准做法是用 DA_jones 作为相对排序变量(如分位数或绝对值排名),不直接引用其点估计。
Python 实现
Python 端用 statsmodels 的 OLS 与 pandas 的 groupby-apply 实现等价回归。
# code/ch03_jones.py
import pandas as pd, numpy as np, statsmodels.api as sm
np.random.seed(2026)
p = pd.read_csv("data/em_panel.csv")
p = p.dropna(subset=["TA","dSale_s","PPE_s","inv_lag_at"])
def jones_resid(df):
X = df[["inv_lag_at","dSale_s","PPE_s"]].values
y = df["TA"].values
beta, *_ = np.linalg.lstsq(X, y, rcond=None)
df = df.copy(); df["DA_jones"] = y - X @ beta
return df
p2 = p.groupby("fyear", group_keys=False).apply(jones_resid)
print(p2["DA_jones"].describe().round(4))
R 与 Python 端 DA_jones 的均值 、标准差 0.186、p10 、p90 0.111 完全一致。
本章累积对比表
表 3·2 累积对比表(第 3 章末)
| 方法 | 样本量 | DA mean | DA sd | 案例公司舞弊年份平均分位 |
|---|---|---|---|---|
| 基线 TA | 119,187 | 0.1920 | —— | |
| Healy 1985 | 119,187 | 0.1910 | Sunbeam 0.17 / CA 0.49 / Enron 0.49 | |
| DeAngelo 1986 | 103,736 | 0.2480 | Sunbeam 0.13 / CA 0.23 / Enron 0.31 | |
| Jones 1991 | 119,187 | 0.1860 | Sunbeam 0.23 / CA 0.01 / Enron 0.53 | |
| Modified Jones | —— | —— | —— | —— |
| PM-DA | —— | —— | —— | —— |
| Dechow-Dichev | —— | —— | —— | —— |
| McNichols | —— | —— | —— | —— |
| Stubben | —— | —— | —— | —— |
| Roychowdhury RM | —— | —— | —— | —— |
| F-Score / ML | —— | —— | —— | —— |
本章知识地图
表 3·3 第 3 章核心概念与常见误解
| 核心概念 | 核心内容 | 常见误解 | 为什么错 |
|---|---|---|---|
| Jones 模型 | 用 1/lag_at、Sale、PPE 三个变量解释 TA,残差为 DA | 残差越大就是操纵越严重 | 残差里还含未被解释的行业、一次性事项与噪声,只能作为相对排序变量 |
| 缩放到 lag_at | 所有变量除以滞后总资产,控制规模异方差 | 缩放是数学技巧,无会计含义 | 缩放后的 TA 是"每单位资产产生的应计",与规模无关的可比指标 |
| 无截距回归 | 截距吸收到 1/lag_at 项,等价于水平方程中允许规模常数 | 没有截距等于强制过原点 | 加 1/lag_at 作为自变量已等价隐含截距,加截距反而 over-fit |
| fyear pooled 简化 | 因 Bao 数据缺 sich,全样本一起按 fyear 跑 | 等价于完整 Jones | 缺少行业固定效应,DA 携带行业偏差,对所有方法的影响方向相同 |
| 平均 0.13 | 销售与固定资产能解释约 13% 的 TA 变异 | 低说明模型不好 | Jones 原文 通常 0.10--0.20,大部分变异留给 DA 是设计目的 |
| 案例公司 | Sunbeam & Enron 在 Jones 下改善,CA 反向 | Jones 普遍优于 Healy | 销售扩张吸收 CA 应收异动,下一章 Modified Jones 把应收扣掉是直接补救 |
小结
本章把 Jones 1991 模型在 Bao 数据上跑通。按 fyear pooled OLS 得到 24 个年度回归,平均 ,DA_jones 全样本绝对值均值 0.0993,比 Healy 模型的 0.104 略低。三家 AAER 案例公司舞弊年份的平均分位 0.258,方向上比 Healy 略有改善但仍不稳定,Computer Associates 2001 年的分位 0.011 反而出乎意料地偏左。原因诊断指向 CA 当年应收账款扩张被 Jones 模型当作合理销售相关应计吸收。下一章 Modified Jones 把应收变化从销售变化中扣掉,正是为了解决这一类问题。