从总应计回到收入
第 3 章到第 7 章的所有方法都建立在总应计 TA 或营运资金应计 WC_accr 之上,差别在解释变量的选择。Stubben 指出这一框架共同的问题:总应计是收入、成本、费用、存货、应付多个会计科目的合成量,每个科目都有不同的可操纵性。把它们打包成一个 TA 然后用销售、CFO 解释,等价于把多种动机的盈余管理压在同一个残差里,单个研究问题(如收入操纵)的识别效率必然下降。
Stubben 的设计简单:如果研究者关心的是收入操纵——管理层通过提前确认收入、虚增交易额、放宽信用政策推高销售——那么直接用应收变化对销售变化回归,残差就是"无法用正常销售扩张解释的应收增长",恰好对应收入操纵的会计机制。这种聚焦让信号更纯,但代价是只覆盖收入侧操纵,不识别费用前置、存货操纵、营业外收益等其他类型的盈余管理。
Stubben 模型的定义
对每个 fyear 跑横截面 OLS:
DA 为残差:。
公式极简:左侧是缩放后的应收变化,右侧是缩放后的销售变化与截距。 是公司 第 年应收账款变化、 是销售变化、 是滞后总资产。其他变量都不进入。
Stubben 原文用了两种形式:一个简化的 revenue model 只用 ,一个扩展的 conditional revenue model 加入公司规模、行业、季度等控制变量。本书采用简化形式,与全书其他章节的解释变量数量保持可比。
在 Bao 数据上的实现
stb_by_year <- p |>
filter(!is.na(dRect_s), !is.na(dSale_s)) |>
group_by(fyear) |>
nest() |>
mutate(
fit = map(data, ~ lm(dRect_s ~ dSale_s, data = .x)),
n = map_int(data, nrow),
r2 = map_dbl(fit, ~ summary(.x)$r.squared)
)
stb_with_da <- stb_by_year |>
mutate(data2 = map2(data, fit, ~ mutate(.x, DA_stb = resid(.y)))) |>
select(fyear, data2) |> unnest(data2) |> ungroup()
跑完得到 24 个年度回归,平均样本量 4,966,平均 。这个 远高于应计型方法,对照来看 Jones 0.131、McNichols 0.148。原因是应收变化与销售变化的会计关系比应计总量与销售的关系紧密得多。应收的会计身份就是赊销累积。
意味着销售变化能解释约 40% 的应收变化变异,剩下 60% 是销售解释不了的应收异动。DA_stb 全样本:n 119,187、均值 (按构造为零)、中位 、标准差 0.0862、绝对值均值 0.0476。绝对值均值 0.0476 比 McNichols 的 0.0762 小 38%,反映 Stubben 模型把可解释的应收变化部分剥离得更彻底,残差更集中。但要记住 Stubben 残差只反映收入侧的可操纵成分,规模不能直接与应计型 DA 比较。
Stubben 模型流程:销售变化 与应收变化 按 fyear 跑 OLS,应收变化作为被解释变量,残差即为收入侧 DA。
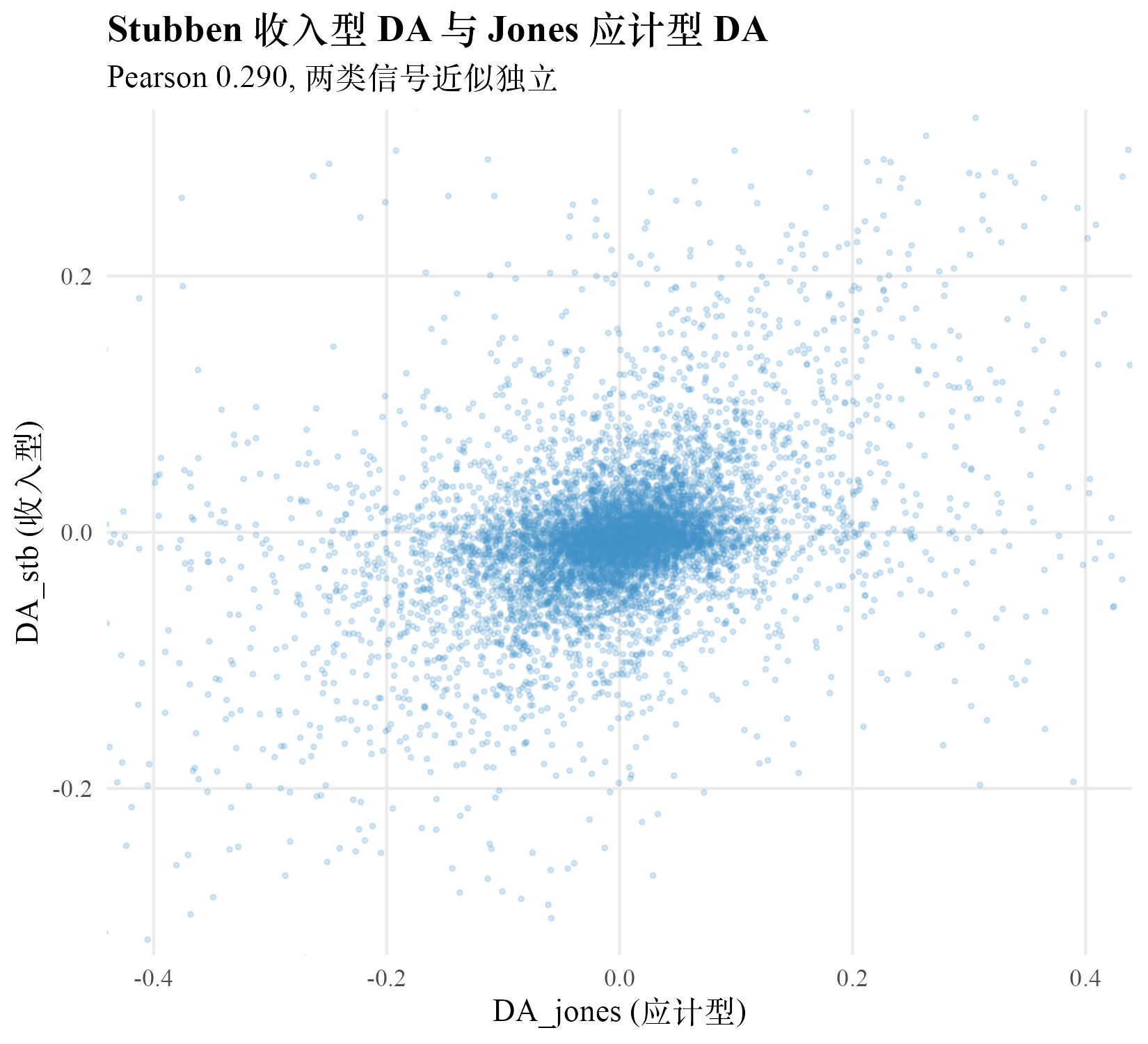
把 DA_stb 与第 3 章 DA_jones 的 firm-year 配对散点画出来。两者 Pearson 相关 0.290,散点云呈圆形而非沿 45 度线,说明 Stubben 收入侧信号与 Jones 应计型信号近似独立。
案例公司在 Stubben 下的表现
表 8·1 案例公司舞弊年份在 Stubben 模型下的 DA 与同年分位
| 公司 | fyear | AAER | DA_stb | rank_stb |
|---|---|---|---|---|
| Sunbeam | 1996 | ✓ | 0.366 | |
| Sunbeam | 1997 | ✓ | 0.141 | |
| Computer Associates | 2001 | ✓ | 0.948 | |
| Enron | 1998 | ✓ | 0.903 | |
| Enron | 1999 | ✓ | 0.519 | |
| Enron | 2000 | ✓ | 0.281 |
数据告诉我们 Stubben 在 Computer Associates 2001 与 Enron 1998 上给出明显的右尾排名。CA 2001 的分位 0.948 是九种方法里 CA 表现最强的,与 SEC 文件所述的"提前确认软件许可证收入、35-day month 操纵"高度一致——CA 操纵的核心就是收入侧。Enron 1998 的分位 0.903 也很高,对应 Enron 通过特殊目的实体虚增交易额的会计后果之一是应收账款异常扩张。
但 Stubben 对 Sunbeam 的判别不理想。Sunbeam 1996 分位 0.366、1997 分位 0.141,都在中位以下。原因是 Sunbeam 1996–1997 的操纵机制以 cookie jar 储备与渠道压货为主,渠道压货虽然涉及应收,但 Sunbeam 在 SEC 文件中被指控的核心是费用与储备操纵,收入侧的信号相对弱。
舞弊年份平均分位:Sunbeam 0.254、Computer Associates 0.948、Enron 0.568,三家平均 0.590。Stubben 在 CA 上的强表现把整体平均拉高到所有应计型方法之上,验证了"针对收入操纵设计的方法在收入操纵公司上识别力更强"这一设计意图。
Stubben 模型完全基于应收与销售的关系,不涉及营业费用、存货、应付、应计折旧。如果一家公司通过推迟营业费用确认、压低存货跌价准备、激进资本化研发支出等机制管理盈余,Stubben 不会给出任何信号。Sunbeam 1996–1997 的部分操纵以费用与减值储备为核心,本章的 Stubben 残差在 Sunbeam 上未能进入右尾,正是这种盲区的实证。诊断方法:研究者使用 Stubben 作为唯一 DA 度量时,必须在论文中明确限定研究问题为收入侧操纵;如果研究问题更广泛(如盈余管理总体强度),需配合 McNichols 或 Modified Jones 等应计型方法。
Python 实现
# code/ch08_stubben.py
import pandas as pd, numpy as np
p = pd.read_csv("data/em_panel.csv").dropna(subset=["dRect_s","dSale_s"])
def stb_resid(df):
X = np.column_stack([np.ones(len(df)), df["dSale_s"].values])
y = df["dRect_s"].values
beta, *_ = np.linalg.lstsq(X, y, rcond=None)
df = df.copy(); df["DA_stb"] = y - X @ beta
return df
p2 = p.groupby("fyear", group_keys=False).apply(stb_resid)
print(p2["DA_stb"].describe().round(4))
R 与 Python 端 DA_stb 的描述统计完全一致。
本章累积对比表
表 8·2 累积对比表(第 8 章末)
| 方法 | 样本量 | DA mean | DA sd | 案例公司舞弊年份平均分位 |
|---|---|---|---|---|
| 基线 TA | 119,187 | 0.1920 | —— | |
| Healy 1985 | 119,187 | 0.1910 | Sunbeam 0.17 / CA 0.49 / Enron 0.49 | |
| DeAngelo 1986 | 103,736 | 0.2480 | Sunbeam 0.13 / CA 0.23 / Enron 0.31 | |
| Jones 1991 | 119,187 | 0.1860 | Sunbeam 0.23 / CA 0.01 / Enron 0.53 | |
| Modified Jones 1995 | 119,187 | 0.1870 | Sunbeam 0.24 / CA 0.09 / Enron 0.44 | |
| PM-DA 2005 | 119,187 | 0.2530 | Sunbeam 0.24 / CA 0.67 / Enron 0.28 | |
| DD 2002 (公司级 AQ) | 7,126 公司 | 0.109 | 0.114 | Sunbeam 0.27 / CA 0.31 / Enron 0.17 |
| McNichols 2002 | 90,189 | 0.150 | Sunbeam 0.35 / CA 0.59 / Enron 0.51 | |
| Stubben 2010 | 119,187 | 0.086 | Sunbeam 0.25 / CA 0.95 / Enron 0.57 | |
| Roychowdhury RM | —— | —— | —— | —— |
| F-Score / ML | —— | —— | —— | —— |
本章知识地图
表 8·3 第 8 章核心概念与常见误解
| 核心概念 | 核心内容 | 常见误解 | 为什么错 |
|---|---|---|---|
| 收入侧 DA | 应收变化对销售变化回归的残差 | 应收异常都是收入操纵 | 还包含赊销政策合理变化、季节性、宏观信贷环境 |
| 0.393 | 销售变化能解释约 40% 的应收变化变异 | 高 说明方法更好 | 与 Jones 系列的 0.13 不可比,因为左侧变量不同 |
| Stubben 设计意图 | 把收入侧操纵从总应计中独立出来 | 与 Modified Jones 等价 | Modified Jones 残差含费用、存货等多重信号,Stubben 残差只含应收异动 |
| 与 Jones 相关 0.29 | 收入侧信号与应计型信号近似独立 | 高相关才说明方法可靠 | 低相关恰好说明两者捕捉不同维度信号,组合使用增量信息更多 |
| CA 2001 右尾 | 分位 0.948 在九种方法中最强 | Stubben 普遍优于 Modified Jones | CA 操纵核心就是收入侧,Stubben 在该机制上设计目的清晰 |
| Sunbeam 中位 | 1996 分位 0.366、1997 分位 0.141 | Stubben 应该识别所有 AAER | Sunbeam 操纵以费用与储备为主,Stubben 对非收入侧操纵盲 |
小结
本章把 Stubben 2010 收入侧 DA 在 Bao 数据上跑通。按 fyear pooled 跑应收变化对销售变化的 OLS,平均 远高于应计型方法,DA_stb 标准差 0.086、绝对值均值 0.0476。三家 AAER 案例公司舞弊年份平均同年分位 0.590,比 McNichols 的 0.482 进一步提升,主要来自 Computer Associates 2001 年的 0.948——CA 操纵的核心机制就是收入侧。但 Stubben 对 Sunbeam 的判别不理想,反映方法学对费用与储备操纵的盲区。Stubben 与 Jones 系列 Pearson 相关 0.29,是九种方法中第一条与应计型路径近似独立的度量。下一章 Roychowdhury 把视角进一步切换到真实经营决策(生产、销售、可酌情费用),是与应计型完全独立的另一类盈余管理。