回到原始问题:怎么把 TA 拆成两部分
第 1 章把 DA 的定义写成 ,其中 NDA 是非操纵性应计。问题就此变成一个估计问题:给定一家公司在第 年的 TA,怎么估出它的 NDA?
最早的两个答案来自 1980 年代中期。Healy (1985) 在研究高管奖金计划对会计选择的影响时,提出用一段估计期内 TA 的样本均值作为 NDA 的估计;DeAngelo (1986) 在研究管理层收购前的会计行为时,提出用上一年的 TA 作为本年 NDA 的估计。两种方法的共同特征是都不需要回归,都只用同一家公司的历史数据。这种简洁性让它们至今仍出现在某些研究场景里,但简洁的代价是对 NDA 的稳定性做出了强假设。本章把这两种方法的内部结构、所需数据、与失稳点逐一展开。
Healy (1985) 模型
核心思想
Healy 假设非操纵性应计在估计期内服从一个未知但稳定的分布。最自然的点估计是估计期内的样本均值。
给定公司 的估计期 与待估期 ,非操纵性应计的 Healy 估计为
对应 DA 为 。
Healy 原文的估计期是同一家公司在分析期之前的若干年,待估期是分析期年度。在大规模面板研究里,由于很多公司没有足够长的历史数据,文献逐渐演化出更实用的横截面变体:以全样本同 fyear 内所有公司的 TA 均值替代单一公司的历史均值。本书采用横截面变体,理由有二:第一,Bao 2020 数据里大约一半公司的可用年份不超过 5 年,按公司算估计期会损失过多样本;第二,横截面 Healy 与本章后面的 Jones 系列方法在计算口径上保持可比性,便于第 10 章交叉比较。
给定 fyear 内的全样本公司集合 ,
。
在 Bao 数据上的实现
横截面 Healy 在 R 里只需要一行 group_by(fyear) 加 mutate(DA = TA - mean(TA))。完整脚本在 code/ch02_healy_deangelo.R。
healy <- p |>
group_by(fyear) |>
mutate(TA_year_mean = mean(TA, na.rm = TRUE),
DA_healy = TA - TA_year_mean) |>
ungroup()
跑完得到 119,187 个 firm-year 的 DA_healy。描述统计如下:均值 (按构造为零)、中位 0.00755、标准差 0.1910、绝对值均值 0.1040。p10 与 p90 分别是 与 。
DA_healy 的均值按定义在每个 fyear 内为零,全样本均值也为零。这是横截面 Healy 的结构特征。绝对值均值 0.1040 大致告诉我们:把一家随机抽取的 firm-year 与同年全样本均值比较,平均偏离 10.4 个百分点。这就是 Healy 视角下的可操纵性应计平均规模。它包含真实的盈余管理,也包含 Healy 模型忽略的行业固定效应、销售增长效应、固定资产强度效应。后续方法把这些效应逐一剥离,绝对值均值会下降。
DeAngelo (1986) 模型
核心思想
DeAngelo 假设非操纵性应计在年度间服从随机游走:。在这一假设下,上一年的 TA 是本年 NDA 的最佳估计。
随机游走假设的会计含义是:管理层在 年的可操纵选择空间,相对于 年的非操纵基准而言。DeAngelo (1986) 原文用这个差分量来研究管理层收购前的会计行为,研究焦点放在临近收购的窗口里应计是否出现异常压低,公司长期应计水平并不在分析对象之内。差分把所有不随时间变化的公司效应消掉,是它相对 Healy 的优势所在。
在 Bao 数据上的实现
DeAngelo 在 R 里也只需要一行:group_by(gvkey) 加 mutate(DA = TA - lag(TA))。
deangelo <- healy |>
arrange(gvkey, fyear) |>
group_by(gvkey) |>
mutate(lag_TA = lag(TA),
DA_deangelo = TA - lag_TA) |>
ungroup()
DeAngelo 损失第一年观测,剩余 103,736 firm-year。描述统计:均值 、中位 、标准差 0.2480、绝对值均值 0.1290、p10 与 p90 分别为 与 。
DeAngelo 的标准差 0.248 比 Healy 的 0.191 高出近 30%,绝对值均值 0.129 也比 Healy 的 0.104 大。这反映差分量天然比偏差量更分散:差分把 与 的随机扰动叠加,方差大约翻倍。这是差分类 DA 估计在统计上的代价。
两种方法的一致性
把同一组 firm-year 上 Healy 与 DeAngelo 的 DA 估计放进同一张散点图,能看到两者高度相关但不重合。Pearson 相关系数 0.6705,Spearman 相关系数 0.5577。这意味着两种方法对哪家公司的 DA 大体一致,但对具体数值有差异。
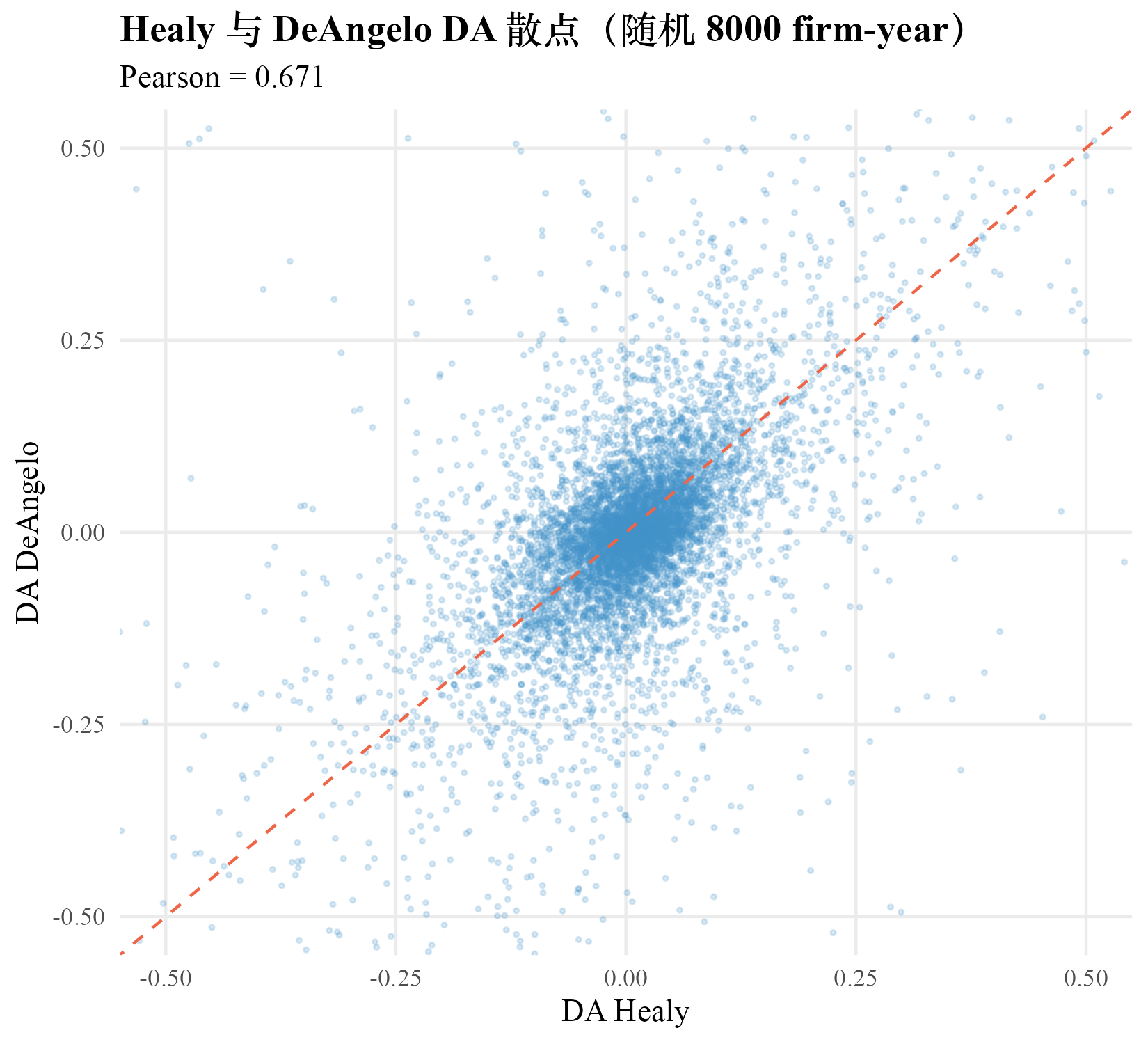
上图的散点云沿 45 度线散开,相关系数 0.67 说明两种方法捕捉的是同一组潜在信号,差异主要来自两类机制:第一,Healy 把 firm-year 与同年所有公司比,DeAngelo 把 firm-year 与同公司上年比,参照系不同;第二,Healy 不损失第一年观测,DeAngelo 损失第一年观测,样本面有所差异。
图 2·2 Healy 与 DeAngelo 在同一份 TA 上的对照流水线。原始 TA 沿两条路径分别减去同 fyear 均值与上一年 TA,得到 DA_healy 与 DA_deangelo 两个估计,最后在 Pearson 0.67 与 Spearman 0.56 的相关性指标上汇合。完整 TikZ 图详见 PDF 全文。
案例公司的初步答案
把三家 AAER 公司在两种方法下的 DA 估计与同年全样本分位列出,能看到一些直观的结果。
表 2·1 案例公司舞弊年份的 DA 估计与同年分位
| 公司 | fyear | AAER | DA_Healy | rank_Healy | DA_DeAngelo | rank_DeAngelo |
|---|---|---|---|---|---|---|
| Sunbeam | 1996 | ✓ | 0.079 | 0.057 | ||
| Sunbeam | 1997 | ✓ | 0.255 | 0.193 | ||
| Computer Associates | 2001 | ✓ | 0.493 | 0.225 | ||
| Enron | 1998 | ✓ | 0.290 | 0.209 | ||
| Enron | 1999 | ✓ | 0.610 | 0.587 | ||
| Enron | 2000 | ✓ | 0.564 | 0.139 |
数据告诉我们:Sunbeam 在 1996–1997 两个被处罚年份里,Healy 与 DeAngelo 都把它排到分布左尾,rank 不到 0.3,与 SEC 起诉书所述压低当期利润、为未来反弹蓄水的方向一致。压低利润意味着压低应计,DA 取负,方向上自洽。Enron 在 1999 年两种方法都排到右尾,rank 在 0.6 以上,但 1998 与 2000 年表现并不显著。Computer Associates 在 2001 年 Healy 排在中位附近、DeAngelo 排在左尾,两种方法不一致。
Sunbeam 的 Healy 平均分位 0.167、DeAngelo 0.125(明显偏左);Enron 的 Healy 平均 0.488、DeAngelo 0.312(围绕中位散开);Computer Associates 的 Healy 0.493、DeAngelo 0.225。除 Sunbeam 外,Healy 与 DeAngelo 并没有把另外两家舞弊公司排到分布的明显尾部。这说明早期方法对真实舞弊的识别能力相当有限,把它们替换为 Jones 模型成为 1990 年代以后文献的主流路径。
两种方法在什么情况下仍然适用
虽然 Jones 系列方法在大多数研究中已经替代 Healy 与 DeAngelo,但两种早期方法在以下三类场景里仍有研究价值。一是事件研究中的窗口对比:当研究关心 IPO 前后、并购前后、管理层变更前后某一短窗口内的 TA 异动,DeAngelo 差分量比 Jones 残差更直观,因为它只对比事件窗与对照窗。二是稳健性检查:现代论文通常把 Jones、Modified Jones 作为主估计,把 Healy、DeAngelo 作为稳健性比对。如果不同方法给出方向相反的结果,研究者会回到原始数据排查。三是小样本研究:当研究样本仅几十或几百 firm-year(如某一行业某一专项研究),跑年度横截面 Jones 回归的样本量不足以让系数稳定,回到 Healy 横截面均值反而更稳健。
DA_healy 在构造上不区分行业、销售增长、固定资产强度,等于把所有横截面异质性都归到 DA。如果研究者忽略这一点,把 DA_healy 直接放进回归模型与公司治理、监管变量做关联,会得到大量来自行业固定效应的虚假显著系数。诊断方法:把 DA_healy 对 SIC 行业哑变量回归,如果 R² 显著大于零,说明 DA_healy 中携带了行业噪声,必须改用控制了行业的 Jones 系列方法。本书因 Bao 数据无 sich 字段不能直接做这个检查,第 3 章引入 Jones 时会从另一角度即 DA_healy 与 DA_jones 的差异回到这件事。
Python 实现
R 与 Python 端的 Healy 与 DeAngelo 输出关键统计量在四位小数上完全一致。Python 端用 pandas 的 groupby.transform 与 shift 实现:
# code/ch02_healy_deangelo.py
import pandas as pd, numpy as np, random
np.random.seed(2026); random.seed(2026)
p = pd.read_csv("data/em_panel.csv")
p["TA_year_mean"] = p.groupby("fyear")["TA"].transform("mean")
p["DA_healy"] = p["TA"] - p["TA_year_mean"]
p = p.sort_values(["gvkey", "fyear"])
p["lag_TA"] = p.groupby("gvkey")["TA"].shift(1)
p["DA_deangelo"] = p["TA"] - p["lag_TA"]
print(p[["DA_healy","DA_deangelo"]].describe())
print("Pearson :",
p[["DA_healy","DA_deangelo"]].corr().iloc[0,1].round(4))
Python 输出的 Pearson 0.6705 与 R 一致。
本章累积对比表
表 2·2 累积对比表(第 2 章末)
| 方法 | 样本量 | DA mean | DA sd | 案例公司平均分位 |
|---|---|---|---|---|
| 基线 TA | 119,187 | 0.1920 | —— | |
| Healy 1985 | 119,187 | 0.1910 | Sunbeam 0.17 / CA 0.49 / Enron 0.49 | |
| DeAngelo 1986 | 103,736 | 0.2480 | Sunbeam 0.13 / CA 0.23 / Enron 0.31 | |
| Jones 1991 | —— | —— | —— | —— |
| Modified Jones | —— | —— | —— | —— |
| PM-DA | —— | —— | —— | —— |
| Dechow-Dichev | —— | —— | —— | —— |
| McNichols | —— | —— | —— | —— |
| Stubben | —— | —— | —— | —— |
| Roychowdhury RM | —— | —— | —— | —— |
| F-Score / ML | —— | —— | —— | —— |
本章知识地图
表 2·3 第 2 章核心概念与常见误解
| 核心概念 | 核心内容 | 常见误解 | 为什么错 |
|---|---|---|---|
| Healy 1985 | 用估计期 TA 均值估非操纵性应计,DA 为偏差量 | 把同年所有公司平均掉就消除了所有非操纵成分 | 仅消除了年度宏观冲击,行业、增长、规模异质性仍然残留在 DA 里 |
| DeAngelo 1986 | 把上一年 TA 当作本年 NDA,DA 为差分量 | 差分量天然不受公司固定效应影响 | 高速成长公司的 NDA 本身随销售扩大而上升,差分会把合理变化误判为 DA |
| Healy 横截面变体 | 用同 fyear 全样本均值替代单公司估计期均值 | 在样本量充足时等价于 Jones 模型 | Jones 显式建模销售与固定资产对 NDA 的影响,横截面均值没有这一控制 |
| 方法间相关 0.67 | Healy 与 DeAngelo 的 DA 同向但不重合 | 高相关意味着两种方法都对 | 高相关只说明捕捉的是同一组潜在信号,两种方法可能同时有偏,本章对三家案例公司的识别率都不令人满意 |
| 案例公司分位 | Sunbeam 1996–1997 落在左尾,Enron 与 CA 表现不稳定 | DA 排名分位可以直接作为舞弊判别阈值 | AAER 标签与实际操纵年份未必完全重合;十种方法将给出的是相对排名集合,不是单点判别 |
| 适用场景 | 事件研究短窗口对比、稳健性检验、小样本研究 | 早期方法已被完全替代 | 文献仍在事件研究与稳健性比对中使用,理解它们是阅读 1980–2000 年间研究的前提 |
小结
本章把 Healy 与 DeAngelo 两个最早期的 DA 度量方法在 Bao 数据上跑通。Healy 横截面变体生成的 DA 均值按构造为零、绝对值均值 0.104;DeAngelo 差分量绝对值均值 0.129,方差比 Healy 高约 30%。两种方法 Pearson 相关 0.67、Spearman 0.56,说明它们捕捉的是同一组信号但参照系不同。在三家 AAER 案例公司上,Sunbeam 的 1996–1997 年被排到分布左尾,与 SEC 文件所述方向一致;Enron 与 Computer Associates 的识别效果不稳定。这一不稳定的根源是两种方法都没有控制行业、销售增长、固定资产强度等横截面异质性,下一章引入的 Jones (1991) 模型把销售变化与固定资产显式放进回归,是本书第一个真正意义上把非操纵性应计与可操纵性应计在结构上分离开的方法。