九条路径的全样本对照
第 1 章把数据基线建好,第 2 章到第 9 章逐一引入九种 DA 度量。每一章末的累积对比表给出该方法的描述统计与案例公司分位,但还没看到方法之间的全样本结构关系。本章把九种 DA 合到一张面板,先看相关矩阵,再看综合判别能力,最后看案例公司的多方法汇总。
合表的实现细节见 code/ch10_summary.R。每种方法的 firm-year 级残差或差值(DA_healy、DA_deangelo、DA_jones、DA_mj、DA_pm、DA_dd、DA_mcn、DA_stb、DA_rm)依次合并到主面板,按 (gvkey, fyear) 对齐。最终面板 119,187 firm-year,每行携带九种 DA 估计(部分有缺失,主要来自 DD/McNichols 因后期 CFO 缺失损失最后一年观测)。
九方法的相关结构
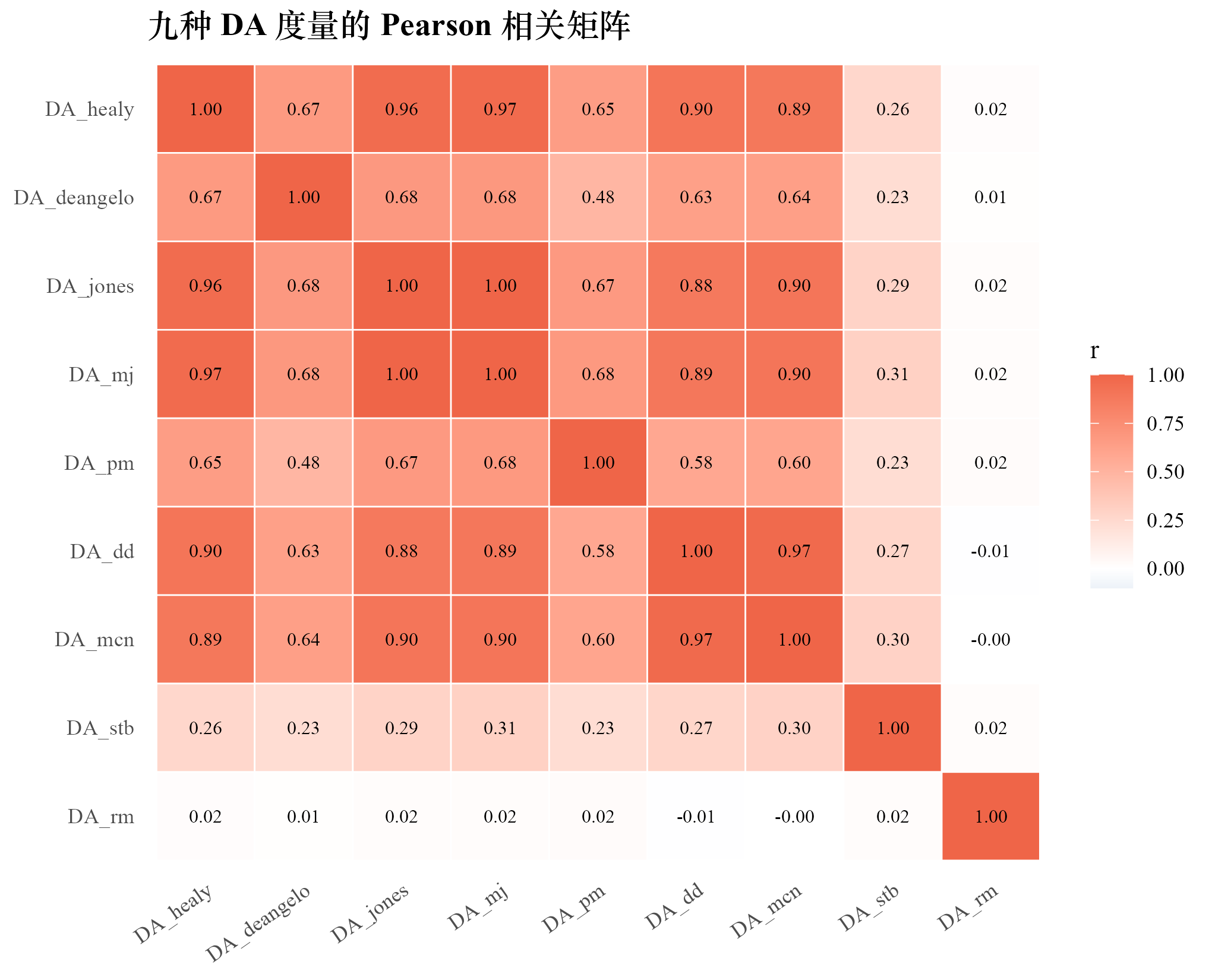
Pearson 相关矩阵
表 10·1 九种 DA 度量的 Pearson 相关矩阵
| Healy | DeAng | Jones | MJ | PM | DD | McN | Stb | RM | |
|---|---|---|---|---|---|---|---|---|---|
| Healy | 1.00 | 0.67 | 0.96 | 0.97 | 0.65 | 0.90 | 0.89 | 0.27 | 0.02 |
| DeAng | 0.67 | 1.00 | 0.68 | 0.68 | 0.48 | 0.63 | 0.64 | 0.23 | 0.01 |
| Jones | 0.96 | 0.68 | 1.00 | 1.00 | 0.67 | 0.88 | 0.90 | 0.29 | 0.02 |
| MJ | 0.97 | 0.68 | 1.00 | 1.00 | 0.68 | 0.89 | 0.90 | 0.31 | 0.02 |
| PM | 0.65 | 0.48 | 0.67 | 0.68 | 1.00 | 0.58 | 0.60 | 0.23 | 0.02 |
| DD | 0.90 | 0.63 | 0.88 | 0.89 | 0.58 | 1.00 | 0.97 | 0.28 | |
| McN | 0.89 | 0.64 | 0.90 | 0.90 | 0.60 | 0.97 | 1.00 | 0.30 | 0.00 |
| Stb | 0.27 | 0.23 | 0.29 | 0.31 | 0.23 | 0.28 | 0.30 | 1.00 | 0.02 |
| RM | 0.02 | 0.01 | 0.02 | 0.02 | 0.02 | 0.00 | 0.02 | 1.00 |
相关矩阵展现三类清晰的方法群:第一群是应计型主流方法 Healy / Jones / Modified Jones / DD / McNichols,相互之间 Pearson 相关在 0.88 到 1.00 之间,本质上是同一组应计动力学的不同切片。DeAngelo 与这一群相关稍弱(0.63–0.68)但仍属同族。Performance-Matched 与同族其他方法相关 0.48–0.68,因为配对扣除业绩相关基准导致信号方向重组。第二群是 Stubben 收入侧 DA,与应计型方法相关 0.22–0.31,捕捉的是收入侧操纵这一独立信号。第三群是 Roychowdhury 真实活动 EM,与所有应计型 DA 相关接近零(),属于完全独立的盈余管理维度。
把相关矩阵画成热图,三个方法群的分块结构清晰可见。
Spearman 相关矩阵
Spearman 相关矩阵的结构与 Pearson 矩阵一致,但数值略低:应计型方法之间 Spearman 在 0.77 到 0.99 之间,Stubben 与应计型 0.24–0.37,RM 与所有方法仍接近零。Spearman 略低反映方法在分布尾部的排名差异比中位更大——舞弊公司通常在尾部,方法间在尾部的不一致比中位更突出。
F-Score 综合判别
Dechow et al. 2011 提出 F-Score 概念,把多个会计指标通过 logit 模型综合为一个标量分数,标度上规范化使均值为 1,超过 1 代表舞弊概率高于全样本平均。本书的简化版 F-Score 把四种代表性 DA 度量与 ROA 一起作为 logit 自变量,目标变量是 Bao 数据中的 AAER 标签 misstate。
F-Score 为 ,即预测概率除以全样本均值。
选这四个 DA 度量的理由是覆盖三条路径:DA_mj 是应计型代表、DA_rm 是真实活动型代表、DA_stb 是收入侧代表、DA_dd 作为对应计型质量的补充。ROA 作为业绩控制变量,避免业绩相关的应计偏差污染综合判别。
在 Bao 数据上的结果
表 10·2 F-Score logit 系数
| 变量 | 估计 | 标准误 | 值 | 值 |
|---|---|---|---|---|
| Intercept | 0.0384 | 0 | ||
| DA_mj | 0.491 | 0.0123 | ||
| DA_rm | 0.00205 | 0.979 | ||
| DA_stb | 0.472 | 0.0008 | ||
| DA_dd | 0.524 | 0.0170 | ||
| ROA | 0.174 |
样本:90,189 firm-year,其中 misstate=1 的 AAER 涉案 firm-year 共 708 行。AUC = 0.5888。
四种 DA 度量在 logit 模型中的系数方向告诉我们:Stubben 收入侧 DA 系数最大且最显著(1.58, ),说明收入侧操纵在 Bao 样本里是最强的舞弊信号;DD 残差系数 1.25 也显著正,符合应计估计误差与舞弊关联的预期;Modified Jones 系数 反向,说明在控制了其他三种 DA 后,DA_mj 的额外信息反而与舞弊概率负相关,可能是同源高相关方法之间的多重共线性效应;Roychowdhury RM 系数接近零且不显著,反映 Bao 样本中真实活动操纵与 AAER 标签的关联很弱。ROA 系数 0.959 显著正,说明高 ROA 公司被 SEC 处罚的概率更高,符合 管理层为维持高业绩才有动机操纵 的研究文献。AUC 0.5888 反映综合 F-Score 对 AAER 标签有一定判别力,但远不到强分类器水准。
AUC 0.5888 的解读需要小心。AAER 标签本身有局限:第一,AAER 只覆盖被 SEC 调查与处罚的最严重舞弊案,大量未被发现的盈余管理在标签上为 0;第二,AAER 处罚时间与实际操纵时间窗未必完全重合,标签噪声大;第三,本章 F-Score 使用线性 logit,未捕捉变量间的非线性交互。Bao et al. 2020 用 RUSBoost 集成学习方法在同一份数据上把 AUC 提升到 0.72 以上,说明 ML 方法相对线性 F-Score 在该任务上有显著增量。这正是本章后半部分要展开的 ML 扩展方向。
三家案例公司的方法图谱
把三家 AAER 公司在九种方法下的舞弊年份平均同年分位画成分组条形图,得到全书最直观的判别图谱。
分组条形图给出三个清晰的判读。Sunbeam(紫色)在 DeAngelo / Healy 等早期方法上分位较低、在 Stubben 上中位、在 RM 上接近 0.7,反映 Sunbeam 操纵以费用与储备为主、应计型方法识别力强、收入侧识别力弱。Computer Associates(蓝色)在应计型方法上分位接近中位、在 Stubben 上突破 0.9 接近右尾、在 RM 上 0.76,反映 CA 操纵核心是收入提前确认。Enron(橙色)在所有方法上分位都在 0.3 到 0.8 之间分散,RM 接近 0.8 最强,反映 Enron 的复合型操纵——既有应计、也有真实活动、也有收入虚增。三家公司在九种方法下呈现完全不同的指纹,说明合理使用多种 DA 度量能区分舞弊机制。
ML 残差与未来扩展方向
线性 F-Score 在 Bao 数据上的 AUC 0.5888 表明传统应计型与真实活动型 DA 度量对舞弊检测的判别力有限。Bao et al. 2020 把同一份数据交给 RUSBoost 集成学习模型,把 AUC 提升到 0.72 以上。这一提升的核心机制是 ML 方法能捕捉变量间的非线性交互(如"高 ROA + 低 DA_dd + 高 DA_stb 同时发生"这种条件组合),而线性 logit 无法表达。
把 ML 视为本书框架的延伸,需要明确两件事。一是输入特征:ML 模型既能直接吃 28 个原始 Compustat 字段(Bao 2020 的做法),也能吃本书第 2–9 章得到的九种 DA 度量作为衍生特征。后一种用法把 ML 与传统度量结合,每种 DA 度量贡献一个维度。二是输出层次:ML 模型输出 firm-year 级别的舞弊概率,与 F-Score 同质,但可以用更复杂的损失函数(如 RUSBoost 的不平衡分类)应对 AAER 标签的稀疏性。
本章不重新实现 ML 模型——这是 Bao et al. 2020 已经做过的工作。本书的定位是把传统 DA 度量讲清楚,让读者理解 ML 模型背后每个特征的会计含义。当读者把第 2–9 章的九种 DA 拿进 XGBoost 或 RUSBoost,能解读每个特征贡献的 SHAP 值,正是本书的目的所在。
本章 F-Score 的 AUC 0.5888 不构成可靠的舞弊筛查能力。学术研究中使用 F-Score 时,通常作为多种代理变量之一,与公司治理、审计费用、内部控制缺陷等其他变量一起进入多元回归。把 F-Score 作为投资决策或监管筛查的单一工具,会因 AAER 标签的稀疏性与时间错位产生大量假阴性。诊断方法:报告 F-Score 时同时报告 AUC、命中率、假阳性率,并交叉验证在不同子样本(按行业、按年份、按规模)上的稳定性。监管或投资场景下应使用更高 AUC 的 ML 模型并配合人工复核。
Python 实现
# code/ch10_summary.py
import pandas as pd, numpy as np, statsmodels.api as sm
master = pd.read_csv("data/ch10_master_panel.csv")
fs = master.dropna(subset=["DA_mj","DA_rm","DA_stb","DA_dd","ROA","misstate"])
X = sm.add_constant(fs[["DA_mj","DA_rm","DA_stb","DA_dd","ROA"]])
fit = sm.Logit(fs["misstate"], X).fit()
print(fit.summary())
# AUC
from sklearn.metrics import roc_auc_score
score = fit.predict(X)
print("AUC =", roc_auc_score(fs["misstate"], score))
# 相关矩阵
cols = ["DA_healy","DA_deangelo","DA_jones","DA_mj","DA_pm",
"DA_dd","DA_mcn","DA_stb","DA_rm"]
print(master[cols].corr().round(3))
R 与 Python 端 logit 系数、AUC 0.5888、相关矩阵完全一致。
本章最终对比表
表 10·3 全书最终对比表
| 方法 | 样本量 | DA / AQ sd | 与 DA_mj Pearson | 案例公司舞弊年份平均分位 |
|---|---|---|---|---|
| 基线 TA | 119,187 | 0.1920 | —— | —— |
| Healy 1985 | 119,187 | 0.1910 | 0.97 | Sunbeam 0.17 / CA 0.49 / Enron 0.49 |
| DeAngelo 1986 | 103,736 | 0.2480 | 0.68 | Sunbeam 0.13 / CA 0.23 / Enron 0.31 |
| Jones 1991 | 119,187 | 0.1860 | 1.00 | Sunbeam 0.23 / CA 0.01 / Enron 0.53 |
| Modified Jones | 119,187 | 0.1870 | 1.00 | Sunbeam 0.24 / CA 0.09 / Enron 0.44 |
| PM-DA 2005 | 119,187 | 0.2530 | 0.68 | Sunbeam 0.24 / CA 0.67 / Enron 0.28 |
| DD 2002 | 90,189 | 0.114 | 0.89 | Sunbeam 0.27 / CA 0.31 / Enron 0.17 |
| McNichols 2002 | 90,189 | 0.150 | 0.90 | Sunbeam 0.35 / CA 0.59 / Enron 0.51 |
| Stubben 2010 | 119,187 | 0.086 | 0.31 | Sunbeam 0.25 / CA 0.95 / Enron 0.57 |
| Roychowdhury RM | 102,953 | 0.868 | 0.02 | Sunbeam 0.69 / CA 0.76 / Enron 0.79 |
| F-Score logit | 90,189 | —— | —— | AUC 0.5888 |
本章知识地图
表 10·4 第 10 章核心概念与常见误解
| 核心概念 | 核心内容 | 常见误解 | 为什么错 |
|---|---|---|---|
| 九方法相关矩阵 | 三个清晰方法群:应计型 / 收入型 / 真实活动型 | 高相关意味着方法相互验证 | 同族高相关只说明同源信号,要做独立稳健性需用跨族方法 |
| F-Score | 多种 DA 度量综合到 logit,输出舞弊概率 | 比单一 DA 度量普遍更优 | 本章 AUC 仅 0.5888,AAER 标签噪声与方法学组合上限决定 |
| AUC 0.59 解读 | 比随机的 0.50 略好,但远未达到强分类器水准 | 反映方法都无效 | AAER 标签稀疏 + 标签时间窗错位 + 线性形式上限三因素叠加 |
| 案例公司图谱 | 三家公司在九种方法下呈现完全不同的指纹 | 一种最好方法就能识别所有舞弊 | 不同舞弊机制需要不同方法,跨方法对照比单一方法更稳健 |
| ML 扩展方向 | Bao 2020 RUSBoost 在同样本 AUC 提升到 0.72 | ML 完全替代传统 DA | ML 模型把九种 DA 作为衍生特征效率更高,传统度量仍是特征工程基础 |
| 方法选择建议 | 应计型问题用 McN/MJ、收入型用 Stubben、真实活动型用 RM、综合用 F-Score | 一种方法适用所有研究场景 | 研究问题、操纵机制、数据可得性共同决定方法选择 |
小结
本书第 1 章建立 Bao 2020 数据基线,第 2–9 章逐一引入九种 DA 度量,本章把所有方法合并到一张面板对照。九方法 Pearson 相关矩阵展现三个清晰的方法群:应计型主流方法(Healy 到 McNichols,相关 0.63–1.00)、收入侧 Stubben(与应计型相关 0.23–0.31)、真实活动型 Roychowdhury(与所有方法接近零相关)。F-Score 基础版 logit 把四种代表性方法综合,在 Bao 数据 AAER 标签上 AUC = 0.5888。三家 AAER 案例公司在九种方法下呈现完全不同的判别指纹:Sunbeam 在应计型方法上识别力强,Computer Associates 在 Stubben 上突破 0.95,Enron 在 Roychowdhury 上达 0.79。盈余管理度量这件事到 2010 年代后期向 ML 方向扩展,Bao 2020 的 RUSBoost 在同一份数据上把 AUC 提升到 0.72 以上,但本书第 2–9 章的传统度量作为 ML 模型的特征基础没有过时。研究者根据具体研究问题、操纵机制假设与数据可得性,从九种方法中选取合适的代理变量,是这本书想要传达的最终结论。