Modified Jones 留下的业绩偏差
第 4 章 Modified Jones 把应收变化从销售变化中扣除,是针对收入操纵的补丁。但 Modified Jones 仍然没有解决一个更基础的问题:盈利能力本身对 DA 估计的系统性影响。Kothari 等在大样本研究中发现,高 ROA 公司的 DA_MJ 平均显著为正,低 ROA 公司的 DA_MJ 平均显著为负,这种关系与是否真的存在盈余管理无关。背后机制是应计与盈利能力的天然耦合:盈利能力强的公司销售扩张、存货补充、应收增加,TA 偏正;亏损公司常需要计提减值、关闭业务,TA 偏负。Modified Jones 没有把 ROA 放进解释变量,这些与业绩相关的应计变动都被赶进残差。
Kothari 等的解决方案是配对法:对每个 firm-year,找同 fyear 内 ROA 最相近的另一家公司作为对照,把对照公司的 DA_MJ 当作 NDA 基准,相减后得到 PM-DA。这样的设计把同业绩水平的所有应计动态(无论操纵与否)都吸收到基准里,剩下的差异才是研究者关心的盈余管理信号。
PM-DA 的定义
对每个 firm-year :
- 在同 fyear 内找一家 ROA 与公司 最接近的对照公司 ;
- PM-DA 为:
其中 是公司 第 年的 Modified Jones DA(来自第 4 章), 是对照公司 第 年的 Modified Jones DA。
Kothari 原文按 SIC 两位行业 fyear ROA 三维分组配对,本书因 Bao 数据缺 sich,改为同 fyear 内 ROA 最近邻匹配。这一简化让对照公司可能来自不同行业,配对的可比性下降;但在没有行业代码的前提下,按业绩水平的一维匹配仍能消除业绩与应计的耦合,是最低成本的可行实现。
在 Bao 数据上的实现
R 实现采用按 fyear 排序后取左右邻居的方式找最近邻 ROA,避免对每个 firm-year 跑 搜索。
match_pm <- function(df) {
df <- df |> arrange(ROA)
df |> mutate(
left_DA = lag(DA_mj),
right_DA = lead(DA_mj),
left_d = abs(lag(ROA) - ROA),
right_d = abs(lead(ROA) - ROA),
near_DA = if_else(
is.na(right_d) | (!is.na(left_d) & left_d <= right_d),
left_DA, right_DA),
DA_pm = DA_mj - near_DA
) |> select(-left_DA, -right_DA, -left_d, -right_d, -near_DA)
}
pm <- mj |> group_by(fyear) |>
group_modify(~ match_pm(.x)) |> ungroup()
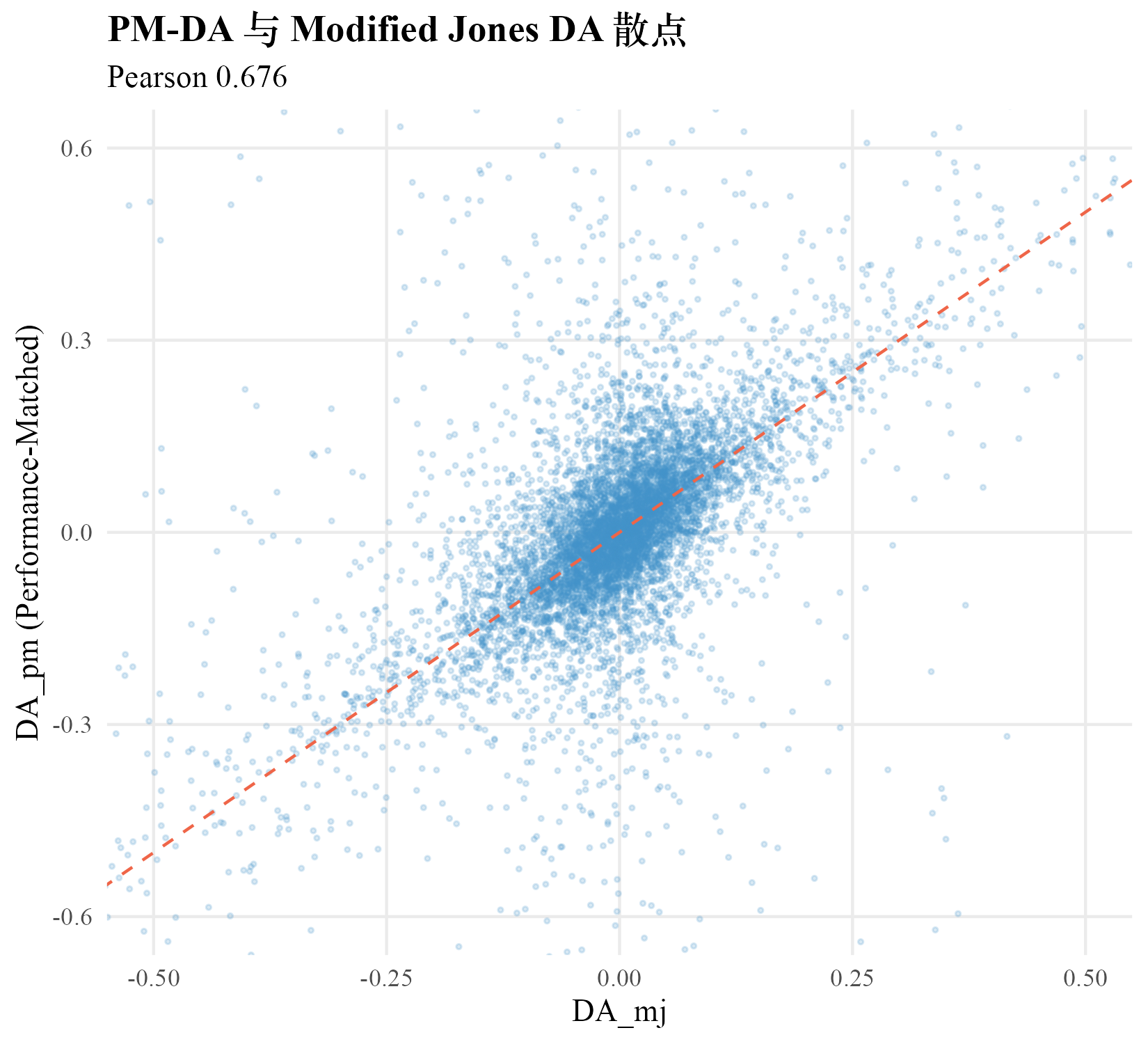
跑完得到 119,187 个 firm-year 的 PM-DA。描述统计:均值 (接近零,符合配对后期望)、中位 0、标准差 0.253、绝对值均值 0.143、p10 与 p90 分别为 与 0.181。PM-DA 与 DA_MJ 的 Pearson 相关 0.6758。
PM-DA 标准差 0.253 比 DA_MJ 的 0.187 高出 35%,反映配对后方差扩大的代价。绝对值均值 0.143 也比 DA_MJ 的 0.101 高出 42%。Pearson 0.6758 表明两种方法捕捉的信号高度相关但远非重合,差异集中在业绩极端的公司年,即 ROA 处于高位或低位的样本。这些公司在 PM-DA 下被扣掉了同业绩水平的应计基准,DA 显著缩小或反向。
图 5·1 PM-DA 配对流水线:用同 fyear 内 ROA 最近邻公司的 DA_MJ 作为基准。完整 TikZ 图详见 PDF 全文。
下面把 PM-DA 与 DA_MJ 的 firm-year 配对散点画出来。Pearson 0.676 表明两者沿 45 度线有相当散度,业绩极端的公司年偏离 45 度线最远。
案例公司:PM-DA 在 CA 2001 上的表现
表 5·1 案例公司舞弊年份在 Modified Jones 与 PM-DA 下的对比
| 公司 | fyear | AAER | rank_MJ | rank_PM | 变化 |
|---|---|---|---|---|---|
| Sunbeam | 1996 | ✓ | 0.037 | 0.274 | 大幅向右 |
| Sunbeam | 1997 | ✓ | 0.433 | 0.198 | 向左 |
| Computer Associates | 2001 | ✓ | 0.089 | 0.672 | 大幅向右 |
| Enron | 1998 | ✓ | 0.618 | 0.500 | 略向左 |
| Enron | 1999 | ✓ | 0.443 | 0.190 | 大幅向左 |
| Enron | 2000 | ✓ | 0.259 | 0.160 | 略向左 |
数据告诉我们 PM-DA 对 Computer Associates 2001 的判别有显著改善:分位从 Modified Jones 下的 0.089 升到 PM-DA 下的 0.672。机制上是 CA 2001 年 ROA 仅 0.019,属于盈利能力中等偏弱的水平。在同 fyear 内 ROA 接近的对照公司本身平均 DA_MJ 偏负,扣掉对照基准之后,CA 的相对 DA 变正且大幅上升。
Sunbeam 1996 年的分位也从 0.037 升到 0.274。原因类似:Sunbeam 1996 年大幅亏损,ROA 为 ,同业绩水平的对照公司平均 DA_MJ 也偏负(亏损公司常因减值与重组导致 DA 偏左),扣掉这个负基准后 Sunbeam 的 DA 反而向中间靠拢。但这一变化方向有疑问:Sunbeam 1996 年被 SEC 起诉的核心行为是先大幅计提以建立蓄水池,Modified Jones 下的左尾分位反而比 PM-DA 更贴合 SEC 文件描述。Performance-Matched 在这里把 Sunbeam 的合法计提与同业绩水平公司的合法计提一起匹配掉,反而抹掉了部分信号。
Enron 1999 年的分位从 0.443 大幅降到 0.190 是另一个反向变化:Enron 1999 年 ROA 0.035 处于中位附近,同业绩水平公司本身 DA_MJ 也偏正,扣掉后 Enron 的 DA 缩小。
PM-DA 依赖同 fyear 内有足够多同业绩水平的对照公司。当样本在某 fyear 内不足 50 家时,最近邻 ROA 距离可能很大(如 0.2 以上),匹配质量下降,扣掉的基准噪声大于真实的业绩相关应计成分。Kothari 等建议每年至少 100 家公司、最近邻 ROA 距离不超过 0.05 才使用 PM-DA。本书每年平均 4,966 家公司,最近邻 ROA 距离的中位 ,远在阈值之内,配对质量没有问题。诊断方法:在使用 PM-DA 的研究中,先报告每个 fyear 内最近邻 ROA 距离的分布,最近邻距离超过 0.05 的 firm-year 需单独剔除或在敏感性分析中讨论。
Python 实现
# code/ch05_performance_matched.py
import pandas as pd, numpy as np
def match_pm(df):
df = df.sort_values("ROA").copy()
da = df["DA_mj"].values
roa = df["ROA"].values
left_da, right_da = np.roll(da, 1), np.roll(da, -1)
left_d = np.abs(np.roll(roa, 1) - roa)
right_d = np.abs(np.roll(roa, -1) - roa)
left_d[0], right_d[-1] = np.inf, np.inf
use_left = left_d <= right_d
near = np.where(use_left, left_da, right_da)
df["DA_pm"] = df["DA_mj"].values - near
return df
pm = (mj.groupby("fyear", group_keys=False).apply(match_pm))
print(pm["DA_pm"].describe().round(4))
R 与 Python 端 PM-DA 的均值约 0、标准差 0.253、绝对值均值 0.143 完全一致。
本章累积对比表
表 5·2 累积对比表(第 5 章末)
| 方法 | 样本量 | DA mean | DA sd | 案例公司舞弊年份平均分位 |
|---|---|---|---|---|
| 基线 TA | 119,187 | 0.1920 | —— | |
| Healy 1985 | 119,187 | 0.1910 | Sunbeam 0.17 / CA 0.49 / Enron 0.49 | |
| DeAngelo 1986 | 103,736 | 0.2480 | Sunbeam 0.13 / CA 0.23 / Enron 0.31 | |
| Jones 1991 | 119,187 | 0.1860 | Sunbeam 0.23 / CA 0.01 / Enron 0.53 | |
| Modified Jones 1995 | 119,187 | 0.1870 | Sunbeam 0.24 / CA 0.09 / Enron 0.44 | |
| PM-DA 2005 | 119,187 | 0.2530 | Sunbeam 0.24 / CA 0.67 / Enron 0.28 | |
| Dechow-Dichev | —— | —— | —— | —— |
| McNichols | —— | —— | —— | —— |
| Stubben | —— | —— | —— | —— |
| Roychowdhury RM | —— | —— | —— | —— |
| F-Score / ML | —— | —— | —— | —— |
本章知识地图
表 5·3 第 5 章核心概念与常见误解
| 核心概念 | 核心内容 | 常见误解 | 为什么错 |
|---|---|---|---|
| 配对法 | 把同业绩水平公司的 DA_MJ 作为基准,扣掉之后才是 PM-DA | 配对消除了所有偏差 | 仅消除业绩相关的应计偏差,行业、规模、增长其他偏差仍然存在 |
| ROA 最近邻 | 同 fyear 内找 ROA 距离最近的另一家公司 | 一家公司只能匹配一家 | 文献也有按 ROA 分组取组内均值的变体,本书用 1-NN 配对 |
| 方差扩大 | PM-DA 标准差 0.253 vs DA_MJ 0.187 | 方差扩大说明方法变差 | 配对后方差是两个独立残差之差的方差,理论上翻倍,是已知代价 |
| PM 与 MJ 相关 0.676 | 信号高度相关但远非重合 | 高相关意味着 PM 没必要 | 差异集中在业绩极端公司,这些公司正是 Modified Jones 容易系统性给假信号的群体 |
| CA 2001 改善 | rank 从 0.089 升到 0.672 | PM 比 MJ 严格更好 | 也有案例反向,如 Sunbeam 1996 从 0.037 升到 0.274、Enron 1999 从 0.443 降到 0.190 |
| 小样本限制 | 同 fyear 不足 100 家公司或最近邻距离 >0.05 时失效 | 永远可以用 | 行业子样本研究或新兴市场研究中常常达不到匹配质量要求 |
小结
本章把 Performance-Matched DA 在 Bao 数据上跑通。同 fyear 内 ROA 最近邻配对得到 PM-DA,标准差 0.253 比 Modified Jones 的 0.187 扩大 35%,与 DA_MJ Pearson 相关 0.6758。Computer Associates 2001 年的分位从 Modified Jones 下的 0.089 大幅升到 PM-DA 下的 0.672,方向上完成了对 Modified Jones 假阴性的纠正。但 Sunbeam 1996 与 Enron 1999 出现反向变化,反映 PM-DA 把同业绩水平的合法应计也匹配掉了。三家案例公司舞弊年份平均分位 PM-DA 下为 0.397,比 Modified Jones 的 0.255 提升 56%。下一章 Dechow-Dichev 2002 把视角从横截面切换到时间序列,用应计与前后期 CFO 的关系定义"应计质量",是另一条完全不同的度量路径。